




[Dacon] 해외 부동산 월세 예측 AI 경진대회 - 앙상블
https://dacon.io/competitions/official/236044/overview/description
데이콘 Basic 해외 부동산 월세 예측 AI 경진대회 - DACON
분석시각화 대회 코드 공유 게시물은 내용 확인 후 좋아요(투표) 가능합니다.
dacon.io
2022년 12월 12일부터 2022년 12월 26일까지 데이콘 Basic 해외 부동산 월세 예측 AI 경진대회가 진행되었다.
비록 참가 기간에 참여하진 못했지만, 연습을 통해 진행할 수 있었다.
성적에는 반영되지 않지만, 내가 짠 모델의 성능을 평가할 수 있다.
간단하게 해외 부동산의 여러 가지 정보를 통해 월세 예측 모델을 만들어 보았다.
해외 부동산 월세 예측 - 앙상블 모델
데이터 불러오기
먼저 데이터를 다운받아 불러와 데이터프레임을 확인해 보자.
import pandas as pd
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
submission = pd.read_csv('sample_submission.csv')
train.head()

총 12개의 컬럼이 있었다.
첫 번째 컬럼인 ID는 의미가 없다고 볼 수 있다.
데이터프레임 재정의(불필요 컬럼 제거)
앞서 말했던 ID 컬럼과 학습데이터에 따로 저장될 타겟 변수인 monthlyRent(us_dollar)의 컬럼을 재정의 해준다.
y = train['monthlyRent(us_dollar)']
train = train.drop(['ID', 'monthlyRent(us_dollar)'], axis = 1)
test = test.drop(['ID'], axis = 1)또한 스케일링에 진행될 변수들 또한 따로 저장해 둔다.
numeric_features = train.select_dtypes(exclude = 'object').columns
categorical_features = train.select_dtypes(include = 'object').columns
print(numeric_features)
print(categorical_features)8개의 숫자형 변수와 2개의 범주형 변수로 나뉜 것을 확인할 수 있다.
결측치 확인
학습을 진행하는데 방해요소인 결측치를 확인한다.
결측치가 0개인 것을 확인할 수 있다.
그러므로 따로 결측치를 처리해줄 필요는 없다.
Scaling
데이터의 스케일을 조정하기 위해 숫자형 변수엔 StandardScaler, 범주형 변수엔 LabelEncoder를 처리해 준다.
StandardScaler란 평균을 0, 분산을 1로 조정시켜주는 것이다.
또한 머신러닝을 돌리기 위해선 범주형 변수들을 모두 숫자형 변수로 처리해줘야 한다.
LabelEncoder를 처리해 준다.
LabelEncoder란 문자열(범주형) 값을 오름차 순으로 정렬 후 0부터 1씩 증가하는 값으로 변환시켜 주는 것이다.
from sklearn.preprocessing import LabelEncoder, StandardScaler
for col in numeric_features:
sc = StandardScaler()
train[col] = sc.fit_transform(train[[col]])
test[col] = sc.fit_transform(test[[col]])
for col in categorical_features:
le = LabelEncoder()
train[col] = le.fit_transform(train[col])
test[col] = le.transform(test[col])변환을 시켜준 뒤 데이터를 다시 확인해 보자.

숫자형 변수에 스케일이 조정되었고, 범주형 변수엔 각 범주에 맞는 숫자가 매핑된 것을 확인할 수 있다.
학습데이터, 검증데이터 나누기
이제 학습에 필요한 데이터셋과 검증에 필요한 데이터셋을 나눠보자.
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_absolute_error
X_tr, X_val, y_tr, y_val = train_test_split(train, y, test_size = 0.2, random_state = 42)
X_tr.shape, y_tr.shape, X_val.shape, y_val.shape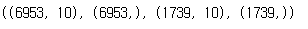
test_size를 통해 전체 데이터의 80%를 학습 데이터, 20%를 검증 데이터로 나눌 수 있다.
이렇게 학습에 필요한 데이터 6953개와 검증에 필요한 데이터 1739개가 나뉜 것을 확인할 수 있다.
모델 검증
이번 글에서는 다양한 모델을 앙상블하여 더 나은 성능을 확인해보고자 한다.
from catboost import CatBoostRegressor
from sklearn.ensemble import RandomForestRegressor
from lightgbm import LGBMRegressor
from xgboost import XGBRegressor
cat = CatBoostRegressor()
rf = RandomForestRegressor()
lgbm = LGBMRegressor()
xgb = XGBRegressor()
cat.fit(X_tr, y_tr)
rf.fit(X_tr, y_tr)
lgbm.fit(X_tr, y_tr)
xgb.fit(X_tr, y_tr)cat_pred = cat.predict(X_val)
rf_pred = rf.predict(X_val)
lgbm_pred = lgbm.predict(X_val)
xgb_pred = xgb.predict(X_val)
final_pred = (cat_pred + rf_pred + lgbm_pred + xgb_pred) / 4
final_pred이렇게 CatBoost, RandomForest, LightGBM, Xgboost의 모델을 사용하였다.
검증 데이터셋 성능 평가
만든 모델의 성능을 평가해 보자.
mean_absolute_error(final_pred, y_val)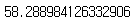
이 대회의 모델 성능 평가는 MAE(Mean Absolute Error)로 진행된다.
MAE란 평균절대오차이며, 모든 절대 오차의 평균을 나타내는 것이다.
절대오차의 평균이기 때문에 낮을수록 모델의 성능이 더 좋다고 볼 수 있다.
이번에 만든 앙상블 모델의 MAE는 58.3으로 나왔다.
1등의 최종 점수가 54.99로 나와 있어 전처리와 모델의 하이퍼파라미터 조정을 통해 더 나은 성능을 기대해 볼 수 있을 것이다.
