




파이썬 데이터 분석 실무 테크닉 100 -최적화(1)
3부 최적화
6장 물류의 최적경로를 컨설팅하는 테크닉 10
분석 목표 : 물류의 기초가 되는 '운송 최적화'를 검토하고 기초적인 테크닉 배우기
전제조건
- 각 창고와 공장 구간의 운송 비용은 과거 데이터에서 정략적으로 계산돼 있음
- 집계 기간은 2019년 1월 1일 ~ 2019년 12월 31일
- 북부지사와 남부지사의 데이처를 시스템에서 추출
테크닉 051 : 물류 데이터를 불러오자
import pandas as pd
# 공장데이터
factories = pd.read_csv('data/6장/tbl_factory.csv', index_col = 0)
factories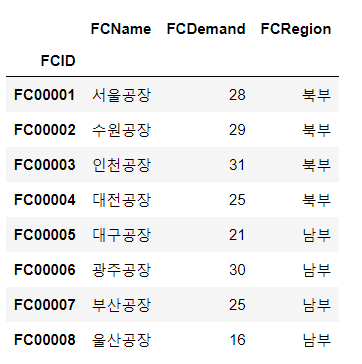
# 창고데이터
warehouse = pd.read_csv('data/6장/tbl_warehouse.csv', index_col = 0)
warehouse
# 비용 테이블
cost = pd.read_csv('data/6장/rel_cost.csv', index_col = 0)
cost

운송 실적 테이블
trans = pd.read_csv('data/6장/tbl_transaction.csv', index_col = 0)
trans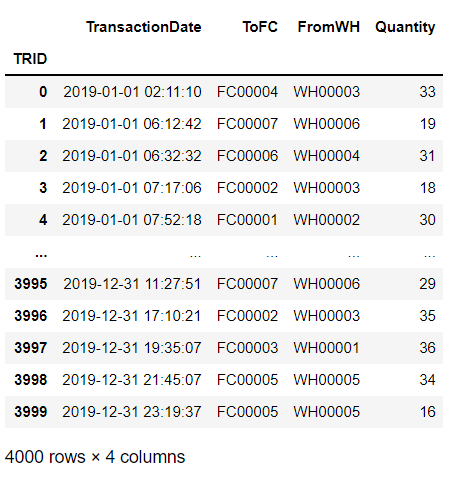
- 공장 데이터 'FCID', 창고 데이터 'WHID'는 비용 데이터나 운송 실적 데이터에도 있는 것으로 보아 이것이 키인 것을 알 수 있다.
- 비용 데이터는 공장과 창고의 조합으로 관리되고 있다.
다음으로 각 운송 실적을 중심으로 레프트 조인을 실시한다.
# 운송실적 테이블에 각 테이블을 조인
# 비용 데이터 추가
join_data = pd.merge(trans, cost, left_on = ['ToFC', 'FromWH'], right_on = ['FCID', 'WHID'], how = 'left')
join_data.head()
# 공장정보 추가
join_data = pd.merge(join_data, factories, left_on = 'ToFC', right_on = 'FCID', how = 'left')
join_data.head()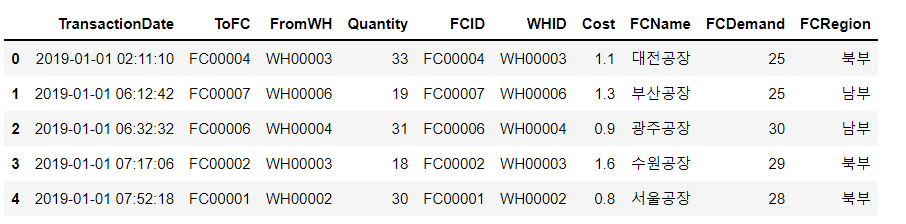
창고 정보도 추가하여 직관적으로 보기 쉽게 칼럼의 순서를 정렬하자.
# 창고정보 추가
join_data = pd.merge(join_data, warehouse, left_on = 'FromWH', right_on = 'WHID', how = 'left')
# 컬럼 정리
join_data = join_data[['TransactionDate', 'Quantity', 'Cost', 'ToFC', 'FCName', 'FCDemand', 'FromWH', 'WHName', 'WHSupply', 'WHRegion']]
join_data.head()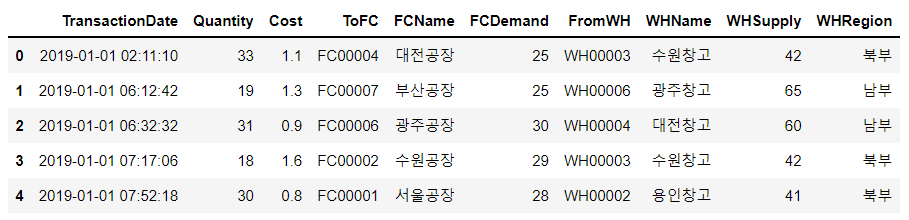
이제 북부지사와 남부지사의 데이터를 비교하기 위해 각각 해당하는 데이터만 추출해서 변수에 저장한다.
north = join_data.loc[join_data['WHRegion'] == '북부']
north.head()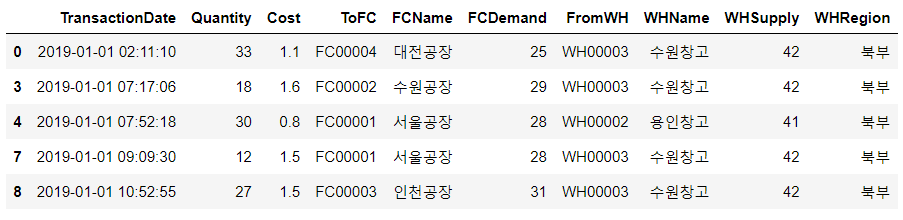
south = join_data.loc[join_data['WHRegion'] == '남부']
south.head()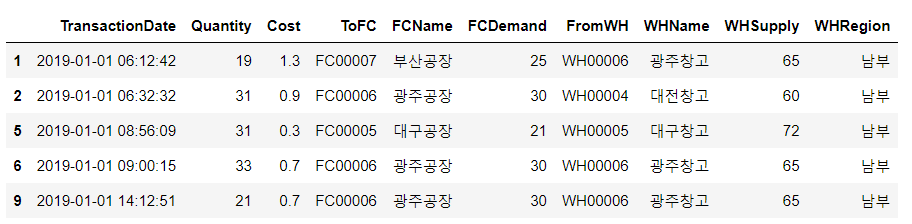
이것으로 데이터 불러오기와 가공이 완료됐다.
테크닉 052 : 현재 운송량과 비용을 확인해 보자
1년간 운송한 부품 수와 비용을 집계해 보자.

북부지사가 남부지사보다 운송 비용의 총액이 많이 소요되는 것을 알 수 있다.
다음으로 1년간 운송 실적으로 실제로 운송한 부품의 수를 집계해 보자.

남부지사가 더 많은 부품을 운송하고 있는 것을 알 수 있다.
다음으로 부품 1개당 운송 비용을 계산해보자.

남부지사가 1개당 운송 비용이 낮을 것을 확인할 수 있다.
다음으로 각 지사의 평균 운송 비용을 계산해 보자.
# 비용을 지사별로 집계
cost_chk = pd.merge(cost, factories, on = 'FCID', how = 'left')
print('북부지사의 평균 운송 비용 : ' + str(cost_chk['Cost'].loc[cost_chk['FCRegion'] == '북부'].mean()) + '원')
print('남부지사의 평균 운송 비용 : ' + str(cost_chk['Cost'].loc[cost_chk['FCRegion'] == '남부'].mean()) + '원')
각 지사의 평균 운송 비용은 거의 같으므로 북부지사보다 남부지사 쪽이 '효율 높게' 부품을 운송하고 있다는 것을 알 수 있다.
테크닉 053 : 네트워크를 가시화해 보자
최적화 문제를 푸는 라이브러리는 여러 가지가 있다. 여기선 최적 경로를 가시화하는 방법인 네트워크 가시화를 배워보자. 여기선 NetworkX라는 라이브러리를 사용할 것이다.
import networkx as nx
import matplotlib.pyplot as plt
# 그래프 객체 생성
G = nx.Graph()
# 노드 설정
G.add_node('nodeA')
G.add_node('nodeB')
G.add_node('nodeC')
# 엣지 설정
G.add_edge('nodeA', 'nodeB')
G.add_edge('nodeA', 'nodeC')
G.add_edge('nodeB', 'nodeC')
# 좌표 설정
pos = {}
pos['nodeA'] = (0, 0)
pos['nodeB'] = (1, 1)
pos['nodeC'] = (0, 1)
# 그리기
nx.draw(G, pos)
# 표시
plt.show()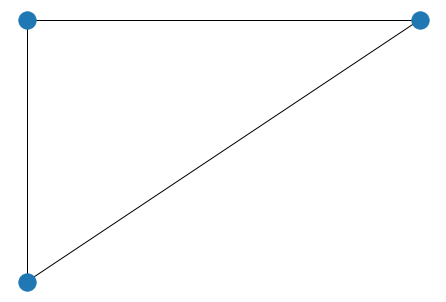
이것이 기본적인 nodeA, nodeB, nodeC를 엣지로 연결해 그린 네트워크이다. 이런 흐름으로 창고에서 대리점까지의 물류를 표현할 수 있다.
테크닉 054 : 네트워크에 노드를 추가해 보자
앞선 네트워크에 nodeD를 추가해 보자.
import networkx as nx
import matplotlib.pyplot as plt
# 그래프 객체 생성
G = nx.Graph()
# 노드 설정
G.add_node('nodeA')
G.add_node('nodeB')
G.add_node('nodeC')
G.add_node('nodeD')
# 엣지 설정
G.add_edge('nodeA', 'nodeB')
G.add_edge('nodeA', 'nodeC')
G.add_edge('nodeB', 'nodeC')
G.add_edge('nodeA', 'nodeD')
# 좌표 설정
pos = {}
pos['nodeA'] = (0, 0)
pos['nodeB'] = (1, 1)
pos['nodeC'] = (0, 1)
pos['nodeD'] = (1, 0)
# 그리기
nx.draw(G, pos)
# 표시
plt.show()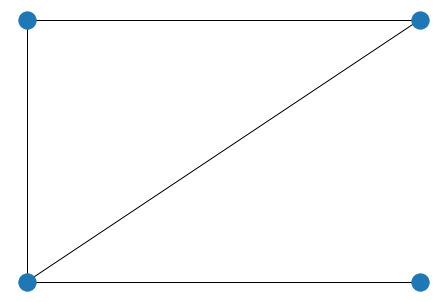
테크닉 055 : 경로에 가중치를 부여하자
가중치를 이용해 노드 사이의 엣지 굵기를 바꾸면 물류의 최적 경로를 알기 쉽게 가시화할 수 있다.
# 데이터 불러오기
df_w = pd.read_csv('data/6장/network_weight.csv')
df_p = pd.read_csv('data/6장/network_pos.csv')
# 엣지 가중치 리스트화
size = 10
edge_weights = []
for i in range(len(df_w)):
for j in range(len(df_w.columns)):
edge_weights.append(df_w.iloc[i][j] * size)
# 그래프 객체 생성
G = nx.Graph()
# 노드 설정
for i in range(len(df_w.columns)):
G.add_node(df_w.columns[i])
# 엣지 설정
for i in range(len(df_w.columns)):
for j in range(len(df_w.columns)):
G.add_edge(df_w.columns[i], df_w.columns[j])
# 좌표 설정
pos = {}
for i in range(len(df_w.columns)):
node = df_w.columns[i]
pos[node] = (df_p[node][0], df_p[node][1])
# 그리기
nx.draw(G, pos, with_labels = True, font_size = 16, node_size = 1000, node_color = 'k', font_color = 'w', width = edge_weights)
# 표시
plt.show()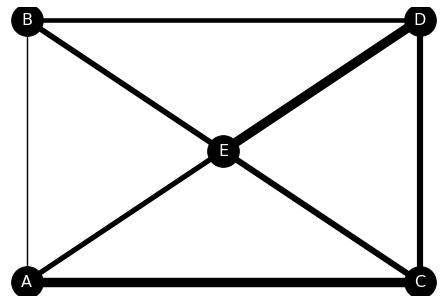
먼저 그래프 객체를 선언하고 노드와 그것을 연결할 엣지, 그리고 노드의 위치를 읽어오게 설정한다. 다음으로 폰트 크기, 노드 크기, 노드 색, 폰트의 색을 지정하고, 마지막으로 width로 엣지의 가중치를 적용하면 가중치를 적용한 엣지를 그릴 수 있다.
간단하게 네트워크 가시화를 알아보았다.
다음 글에서 본격적으로 물류 데이터를 이용해 최적화를 진행할 것이다.
'파이썬' 카테고리의 다른 글
| 파이썬 데이터 분석 실무 테크닉 100 -최적화(3) (0) | 2021.09.23 |
|---|---|
| 파이썬 데이터 분석 실무 테크닉 100 -최적화(2) (0) | 2021.09.14 |
| [파이썬 실습] 정규화 모델 실습(2) (0) | 2021.06.07 |
| [파이썬 실습] 정규화 모델 실습(1) (0) | 2021.06.05 |
| [빅데이터분석기사 실기] - 작업형 1유형 (0) | 2021.06.04 |
