Edwith 강의를 통해 [캐글 실습으로 배우는 데이터 사이언스] 강의를 들었다. 교육 과정에 자전거 수요 예측 강의를 듣고 캐글 실습을 시작하게 되었다. 기초로 진행하기엔 좋은 데이터 분석이라 생각하여 직접 캐글로 진행해보았다.
데이터셋은 아래의 링크에 있다.
https://www.kaggle.com/c/bike-sharing-demand
Bike Sharing Demand | Kaggle
www.kaggle.com
1. 모듈 불러오기
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from scipy import stats
import matplotlib as mpl
%matplotlib inline
plt.style.use('ggplot')
# 한글 폰트 입력
plt.rc('font', family = 'Malgun Gothic')
sns.set(font = 'Malgun Gothic',
rc = {'axes.unicode_minus':False},
style = 'darkgrid')
import warnings
warnings.filterwarnings('ignore')중간에 한글 폰트를 입력하기 위해 plt.rc('font', family = 'Malgun Gothic)을 사용하였다.
2. 데이터 불러오기
train = pd.read_csv('data/bike_train.csv', parse_dates = ['datetime'])
train.shape
데이터를 불러오고 parse_dates 함수를 통해 날짜를 datetime 형태로 지정했다.
다음으로 train 데이터셋에 정보를 확인해보았다.
train.info()
총 데이터 개수는 10886개이고 피처 수는 12개이다. 결측치가 하나도 없는 완전한 데이터셋이다.
데이터를 살펴보면 season의 경우 봄, 여름, 가을, 겨울 순으로 1, 2, 3, 4으로 정렬돼있고, holiday는 휴일, workingday는 일하는 날로 분류하고 temp는 그 시간의 온도, atemp는 체감온도, windspeed는 풍속이다. count는 그 시간에 대여한 자전거 수를 뜻한다.
train.head()
3. EDA
일단 temp 피처를 살펴보자.
train['temp'].describe()
평균 온도는 20.2도이고 최대 온도는 41도이다.
missingno 패키지를 통해 train 데이터셋의 결측치 여부를 확인해보자.
import missingno as msno
msno.matrix(train, figsize = (12, 5))
결측치는 없다. 그럼 데이터 전처리를 진행한다.
train['year'] = train['datetime'].dt.year
train['month'] = train['datetime'].dt.month
train['day'] = train['datetime'].dt.day
train['hour'] = train['datetime'].dt.hour
train['minute'] = train['datetime'].dt.minute
train['second'] = train['datetime'].dt.second
train.shape날짜 데이터를 연, 월, 일, 시간, 분, 초로 나누었다.
그래프를 통해 연도별, 월별, 일별, 시간별로 대여량을 체크해보자.
figure, ((ax1, ax2, ax3), (ax4, ax5, ax6)) = plt.subplots(nrows = 2, ncols = 3)
figure.set_size_inches(18, 8)
sns.barplot(data = train, x = 'year', y = 'count', ax = ax1)
sns.barplot(data = train, x = 'month', y = 'count', ax = ax2)
sns.barplot(data = train, x = 'day', y = 'count', ax = ax3)
sns.barplot(data = train, x = 'hour', y = 'count', ax = ax4)
sns.barplot(data = train, x = 'minute', y = 'count', ax = ax5)
sns.barplot(data = train, x = 'second', y = 'count', ax = ax6)
ax1.set(ylabel = 'Count', title = '연도별 대여량')
ax2.set(ylabel = 'month', title = '월별 대여량')
ax3.set(ylabel = 'day', title = '일별 대여량')
ax4.set(ylabel = 'hour', title = '시간별 대여량')
- 그래프를 살펴보면 연도별 대여량은 2011년보다 2012년이 더 많았다.
- 월별 대여량은 6월에 가장 많고, 7 ~ 10월도 대여량이 많다. 그리고 1월에 가장 적었다.
- 일별 대여량은 1일부터 19일까지만 있고 뒤에 31일까진 test 데이터셋에 있었다. 그래서 이 데이터는 피처로 사용하면 안 된다.
- 시간 대 대여량을 보면 출퇴근 시간에 대여량이 많았다. 하지만 주말과 나누어 볼 필요가 있다.
- 분, 초는 다 0이기 때문에 의미가 없는 것으로 보인다.
다음은 대여량, 계절별 대여량, 시간별 대여량, 근무일 여부에 따른 대여량을 살펴보자.
fig, axes = plt.subplots(nrows = 2, ncols = 2)
fig.set_size_inches(12, 10)
sns.boxplot(data = train, y = 'count', orient = 'v', ax = axes[0][0])
sns.boxplot(data = train, y = 'count', x = 'season', orient = 'v', ax = axes[0][1])
sns.boxplot(data = train, y = 'count', x = 'hour', orient = 'v', ax = axes[1][0])
sns.boxplot(data = train, y = 'count', x = 'workingday', orient = 'v', ax = axes[1][1])
axes[0][0].set(ylabel = 'Count', title = '대여량')
axes[0][1].set(xlabel = 'Season', ylabel = 'Count', title = '계절별 대여량')
axes[1][0].set(xlabel = 'Hour Of The Day', ylabel = 'Count', title = '시간별 대여량')
axes[1][1].set(xlabel = 'Working Day', ylabel = 'Count', title = '근무일 여부에 따른 대여량')
대여량은 70 ~ 300대 사이에 분포했다. 계절별 대여량의 경우 겨울의 대여량이 가장 적었고, 여름, 가을이 대체적으로 많았다. 시간별 대여량은 출근시간과 주로 저녁시간에 많이 이루어졌다. 근무일 여부에 따른 대여량 경우 휴일의 대여량이 근무일 대여량보다 근소하게 많았다.
다음으로 dayofweek를 사용해 일 별로 데이터를 나누어보자.
train['dayofweek'] = train['datetime'].dt.dayofweek
train.shape
피처 수는 19개로 늘었다.
그래프를 통해 시간별 대여량을 변수에 따라 알아보자.
fig, (ax1, ax2, ax3, ax4, ax5) = plt.subplots(nrows = 5)
fig.set_size_inches(18, 25)
sns.pointplot(data = train, x = 'hour', y = 'count', ax = ax1)
sns.pointplot(data = train, x = 'hour', y = 'count', hue = 'workingday', ax = ax2)
sns.pointplot(data = train, x = 'hour', y = 'count', hue = 'dayofweek', ax = ax3)
sns.pointplot(data = train, x = 'hour', y = 'count', hue = 'weather', ax = ax4)
sns.pointplot(data = train, x = 'hour', y = 'count', hue = 'season', ax = ax5)
그래프를 보면 위의 분석 결과와 같은 의미를 가진다.
다음으로 히트맵을 통해 연관관계를 살펴보자.
fig, ax = plt.subplots()
fig.set_size_inches(20,10)
sns.heatmap(corrMatt, mask = mask, vmax = 0.8, square = True, annot = True)
히트맵을 통해 본 결과이다.
- 온도, 습도, 풍속은 연관관계가 거의 없다고 볼 수 있다.
- 대여량과 가장 연관이 높은 건 registered로 등록된 대여자가 많지만, test 데이터에는 이 값이 없다.
- atemp와 temp는 0.98로 상관관계가 높지만 온도와 체감온도로 피처를 사용하기에 적합하지 않을 수 있다.
다음은 산점도를 통해 확인해보자.
fig, (ax1, ax2, ax3) = plt.subplots(ncols = 3)
fig.set_size_inches(12, 5)
sns.regplot(x = 'temp', y = 'count', data = train, ax = ax1)
sns.regplot(x = 'windspeed', y = 'count', data = train, ax = ax2)
sns.regplot(x = 'humidity', y = 'count', data = train, ax = ax3)
- 풍속의 경우 0에 숫자가 몰려 있는 것으로 보인다. 아마도 관측되지 않은 수치에 대해 0으로 기록된 것이 아닐까 추측해본다.
다음으로 년, 월을 합쳐 새로운 피처를 만들어 확인해보자.
def concatenate_year_month(datetime):
return "{0}-{1}".format(datetime.year, datetime.month)
train['year_month'] = train['datetime'].apply(concatenate_year_month)
print(train.shape)
train[['datetime', 'year_month']].head()
위에 만든 피처를 통해 그래프를 그려 확인해본다.
fig, (ax1, ax2) = plt.subplots(nrows = 1, ncols = 2)
fig.set_size_inches(18, 4)
sns.barplot(data = train, x = 'year', y = 'count', ax = ax1)
sns.barplot(data = train, x = 'month', y = 'count', ax = ax2)
fig, ax3 = plt.subplots(nrows = 1, ncols = 1)
fig.set_size_inches(18, 4)
sns.barplot(data = train, x = 'year_month', y = 'count', ax = ax3)
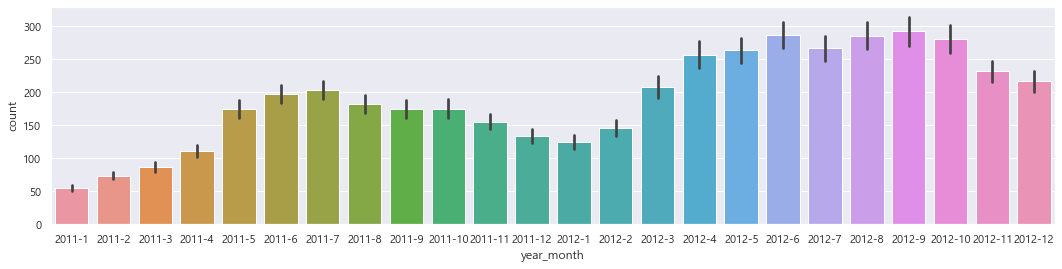
- 2011년보다 2012년의 대여량이 더 많은 것을 확인할 수 있다.
- 겨울보다는 여름에 대여량이 많다.
- 2011년과 2012년의 월별 데이터를 이어 보면 전체적으로 증가하는 추세임을 확인할 수 있다.
다음으로 이상치를 제거한다.
이상치 제거 방법으로 IQR을 통해 Q3 + IRQ * 1.5를 사용해 이상치를 제거한다.
trainWithoutOutliers = train[np.abs(train['count'] - train['count'].mean()) <= (3 * train['count'].std())]
print(train.shape)
print(trainWithoutOutliers.shape)figure, axes = plt.subplots(ncols = 2, nrows = 2)
figure.set_size_inches(12, 10)
sns.distplot(train['count'], ax = axes[0][0])
stats.probplot(train['count'], dist = 'norm', fit = True, plot = axes[0][1])
sns.distplot(np.log(trainWithoutOutliers['count']), ax = axes[1][0])
stats.probplot(np.log1p(trainWithoutOutliers['count']), dist = 'norm', fit = True, plot = axes[1][1])
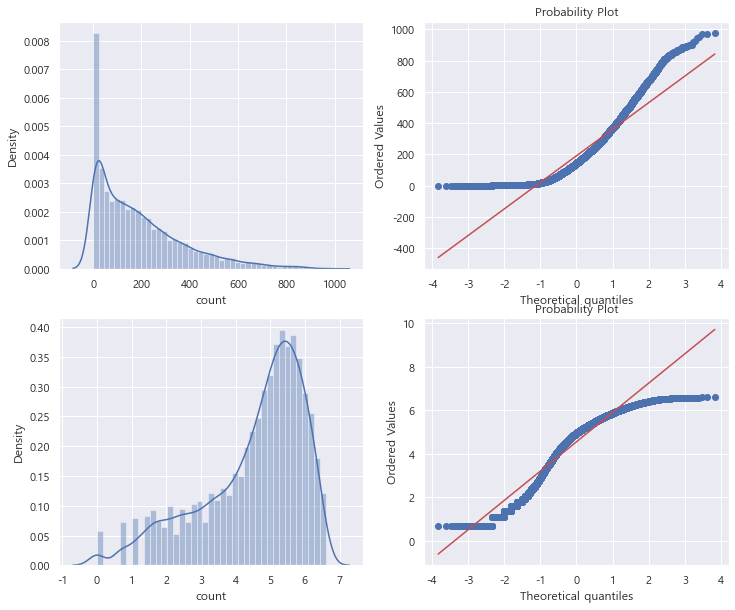
데이터 분포도를 파악해보면 count 변수가 오른쪽에 치우쳐져 있다. 대부분의 기계학습은 종속변수가 normal이어야 하기에 정규분포를 갖는 것이 바람직하다. 대안으로 outlier data를 제거하고 count 변수에 로그를 씌워 변경해 봐도 정규분포를 따르지는 않지만 이전 그래보다 좀 더 자세히 표현하는 것을 알 수 있다.
'Kaggle' 카테고리의 다른 글
| [샌프란시스코 범죄 분류] - 1 (0) | 2021.10.05 |
|---|---|
| [진짜 재난 뉴스 판별기] - 2 (0) | 2021.10.04 |
| [진짜 재난 뉴스 판별기] - 1 (0) | 2021.10.01 |
| [타이타닉 생존자 분류] - 2 (0) | 2021.09.09 |
| [타이타닉 생존자 분류] - 1 (0) | 2021.09.08 |