2부 머신러닝
3장 고객의 전체 모습을 파악하는 테크닉 10
분석 목표 : 머신러닝을 하기 위한 데이터 가공 시술을 배우면서 고객 행동을 분석하고 파악하는 노하우 배우기
전제조건
- 종일 회원, 주간 회원, 야간 회원으로 구분
| No. | 파일 이름 | 개요 |
| 1 | use_log.csv | 센터의 이용 이력 데이터, 기간은 2018년 4월 ~ 2019년 3월 |
| 2 | customer_master.csv | 2019년 3월 말 시점의 회원 데이터 |
| 3 | class_master.csv | 회원 구분 데이터(종일, 주간, 야간) |
| 4 | campaign_master.csv | 행사 구분 데이터(입회비 유무) |
테크닉021 : 데이터 읽기
import pandas as pd
uselog = pd.read_csv('use_log.csv')
print(len(uselog))
uselog.head()customer = pd.read_csv('customer_master.csv')
print(len(customer))
customer.head()class_master = pd.read_csv('class_master.csv')
print(len(class_master))
class_master.head()campaign_master = pd.read_csv('campaign_master.csv')
print(len(campaign_master))
campaign_master.head() |
 |
 |
 |
- uselog는 고객 ID, 이용일을 포함한 간단한 데이터라는 것을 알 수 있다.
- customer에는 고객 ID, 회원 클래스, 성별, 등록일 정보가 들어 있다. 또한 is_deleted 열은 2019년 3월 시점에 탈퇴한 유저를 시스템에서 빨리 찾기 위한 칼럼이다.
- 회원 구분, 캠페인 구분 데이터는 각각 구분할 수 있는 내용이 데이터에 포함되어 있으며, 각각 class와 campaign_id를 이용하면 회원 데이터와 결합할 수 있을 것이다.
테크닉022 : 고객 데이터 가공하기
테크닉021에서 불러온 customer에 회원 구분 class_master와 캠페인 구분 campaign_master를 결합해서 customer_join을 새로 생성한다. 고객 데이터를 중심으로 가로로 결합하는 레프트 조인이다.
customer_join = pd.merge(customer, class_master, on = 'class', how = 'left')
customer_join = pd.merge(customer_join, campaign_master, on = 'campaign_id', how = 'left')
customer_join.head()
조인할 때 키가 없거나 조인이 잘못되면 자동으로 결측치가 들어가다. 그래서 조인 후에는 결측치를 확인해야 한다.
# 결측치 확인
customer_join.isnull().sum()
end_date 외에는 결측치가 0이므로, 이번 조인에서 추가한 데이터는 정확하게 들어 있는 것을 확인했다.
end_date에 결측이 있는 이유는 탈퇴하지 않은 회원의 탈퇴일이 공백이기 때문이라고 생각할 수 있다.
테크닉023 : 고객 데이터 집계하기
데이터 가공을 완료했으니 고객 데이터를 집계해서 전체 모습을 살펴보자.

위에 실행결과를 살펴보면, 종일반이 절반을 차지하고 야간 다음 주간 순이다. 캠페인은 일반 입회가 많고, 입회 캠페인에 의한 가입이 약 20%에 해당한다. 남녀 비율은 남자가 약간 많다는 것을 알 수 있다.
다음으로 start_date가 2018년 4월 1일 이후부터 2019년 3월 31일까지인 가입 인원을 집계해보자.
# start_date가 2018년 4월 1일 이후부터 2019년 3월 31일까지인 가입 인원을 집계
customer_join['start_date'] = pd.to_datetime(customer_join['start_date'])
customer_start = customer_join.loc[customer_join['start_date'] > pd.to_datetime('20180401')]
print(len(customer_start))
이 기간동안의 가입인원이 1361명인 것을 확인할 수 있다.
테크닉024 : 최신 고객 데이터 집계하기
최근 월로 추출하기 위해서는 2019년 3월에 탈퇴한 고객과 재적 중인 고객을 추출하자.
# 가장 최근 월(2019년 3월)의 고객 데이터를 파악하기
## 가장 최근 월의 고객만 추출하기
customer_join['end_date'] = pd.to_datetime(customer_join['end_date'])
customer_newer = customer_join.loc[(customer_join['end_date'] >= pd.to_datetime('20190331')) | (customer_join['end_date'].isna())]
print(len(customer_newer))
customer_newer['end_date'].unique()
여기서 NaT는 datetime형의 결측치라는 의미로, 여기서는 탈퇴하지 않은 고객을 나타낸다.
그리고 회원 구분, 캠페인 구분, 성별로 전체를 파악해보자.

출력 결과를 확인해보면 회원 구분 및 성별은 테크닉023에서 전체를 집계했을 때와 비율이 크게 다르지 않다. 이것은 즉, 특정 회원 구분이나 성별이 탈퇴한 것이 아니라고 생각할 수 있다. 캠페인 구분은 약간 차이가 있어, 전체를 집계했을 때는 일반으로 입회한 유저가 약 72%였던 것에 반해, 일반 입회 회원 비율은 약 81%를 나타낸다. 이것은 입회 캠페인은 회원 비율 변화에 영향을 미친다고 추측할 수 있다.
테크닉025 : 이용 이력 데이터를 집계하기
먼저 간단히 시간적인 요소를 도입하고, 월 이용 횟수의 평균값, 중앙값, 최댓값, 최솟값과 정기적 이용 여부를 플래그로 작성해서 고객 데이터에 추가한다.
# 월 이용 횟수의 평균값, 중앙값, 최댓값, 최솟값과 정기적 이용 여부를 플래그로 작성해서 고객 데이터에 추가하기
uselog['usedate'] = pd.to_datetime(uselog['usedate'])
uselog['연월'] = uselog['usedate'].dt.strftime('%Y%m')
uselog_months = uselog.groupby(['연월', 'customer_id'], as_index = False).count()
uselog_months.rename(columns = {'log_id' : 'count'}, inplace = True)
del uselog_months['usedate']
uselog_months.head()
그리고 고객 별로 평균값, 중앙값, 최댓값, 최솟값을 집계해 보자.
# 고객별로 평균값, 중앙값 최댓값, 최솟값 집계하기
uselog_customer = uselog_months.groupby('customer_id').agg(['mean', 'median', 'max', 'min'])['count']
uselog_customer = uselog_customer.reset_index(drop = False)
uselog_customer.head()
1행에서 groupby로 평균값, 중앙값, 최댓값, 최솟값을 집계한다. 2행에서는 groupby의 영향으로 customer_id가 index에 들어 있기 때문에 칼럼으로 변경한다. 고객 AS002855의 평균값 4.5, 중앙값 5, 최댓값 7, 최솟값 2인 것을 알 수 있다.
테크닉026 : 이용 이력 데이터로부터 정기 이용 플래그를 작성하기
스포츠 센터의 경우 지속 요소 중 하나로 습관을 생각할 수 있다. 이 데이터에서는 매주 같은 요일에 왔는지 아닌지로 판단한다. 월별 정기적 이용 여부는 고객에 따라 다르겠지만, 고객마다 월/요일별로 집계하고 최댓값이 4 이상인 요일이 하나라도 있는 회원은 플래그를 1로 처리한다.
# 고객마다 월 / 요일별로 집계
uselog['weekday'] = uselog['usedate'].dt.weekday
uselog_weekday = uselog.groupby(['customer_id', '연월', 'weekday'],
as_index = False).count()[['customer_id', '연월', 'weekday', 'log_id']]
uselog_weekday.rename(columns = {'log_id' : 'count'}, inplace = True)
uselog_weekday.head()
1행은 요일을 숫자로 변환하고, 0에서 6까지의 숫자는 각각 월요일부터 일요일에 해당한다. 2행에서는 고객, 연월, 요일별로 log_id를 카운트한다. 회원 AS002855를 보면 2018년 4월에 토요일에 4번, 2018년 5월에도 토요일에 4번에 간 것을 확인할 수 있으므로, 매주 토요일에 체육관에 오는 것이라고 생각할 수 있다.
이제 고객별로 최댓값을 계산하고, 그 최댓값이 4 이상인 경우에 플래그를 지정해보자.
# 고객별로 최댓값 계산하고, 그 최댓값이 4 이상인 경우에 플래그 지정
uselog_weekday = uselog_weekday.groupby('customer_id', as_index = False).max()[['customer_id', 'count']]
uselog_weekday['routine_flg'] = 0
uselog_weekday['routine_flg'] = uselog_weekday['routine_flg'].where(uselog_weekday['count'] < 4, 1)
uselog_weekday.head()
1행에서 고객 단위로 집계하고 최댓값을 구한다. 특정 월, 특정 요일에 가장 많이 이용한 횟수이다.
2행에서는 routine_flg에 0을 입력하고 3행에서는 횟수가 4 미만인 경우는 0을 그대로 두고 4 이상인 경우 1을 대입한다.
테크닉027 : 고객 데이터와 이용 이력 데이터 결합하기
uselog_customer, uselog_weekday를 customer_join과 결합하자.
customer_join = pd.merge(customer_join, uselog_customer, on = 'customer_id', how = 'left')
customer_join = pd.merge(customer_join, uselog_weekday[['customer_id', 'routine_flg']], on = 'customer_id', how = 'left')
customer_join.head()
두 번에 걸쳐 결합을 하였고, 결합에 사용한 조인키는 customer_id, 결합 방법은 레프트 조인이다.
결합한 데이터의 결측치를 확인하자.

마찬가지로 end_date 이외에는 결측치가 없는 것을 보아 결합이 잘 되었다고 볼 수 있다.
테크닉028 : 회원 기간 계산하기
회원 기간은 단순히 start_date와 end_date의 차이이다. 하지만 2019년 3월까지 탈퇴하지 않은 회원은 end_date에 결측치가 들어 있기 때문에 그 차이를 계산할 수 없다. 그래서 탈퇴하지 않은 회원은 2019년 4월 30일로 채워서 회원 기간을 계산한다.
from dateutil.relativedelta import relativedelta
customer_join['calc_date'] = customer_join['end_date']
customer_join['calc_date'] = customer_join['calc_date'].fillna(pd.to_datetime('20190430'))
customer_join['membership_period'] = 0
for i in range(len(customer_join)):
delta = relativedelta(customer_join['calc_date'].iloc[i], customer_join['start_date'].iloc[i])
customer_join['membership_period'].iloc[i] = delta.years*12 + delta.months
customer_join.head()
1행에서 날짜 비교 함수 relativedelta를 사용하기 위해 라이브러리를 임포트했다. 2행에서는 날짜 계산용 칼럼을 end_date를 기준으로 작성하고 3행에서 결측치에 2019년 4월 30일을 대입한다. 그다음 회원 기간을 월 단위로 계산해 칼럼을 추가한다.
테크닉029 : 고객 행동의 각종 통계량을 파악하기
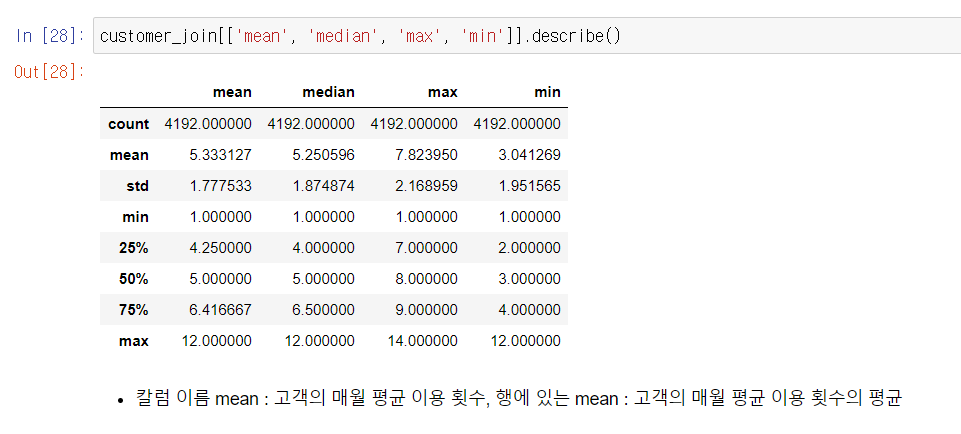
데이터 가공으로 추가한 mean, median, max, min을 describe를 이용해서 파악하자.
routine_flg도 집계해보자.

마지막으로 회원 기간의 분포를 히스토그램으로 살펴보자.
import matplotlib.pyplot as plt
%matplotlib inline
plt.hist(customer_join['membership_period'])
히스토그램을 보면 회원 기간이 10개월 이내인 고객이 많고, 10개월 이상의 고객 수는 거의 일정한 것을 알 수 있다. 이것은 즉, 짧은 기간에 고객이 빠져나간다고 볼 수 있다.
테크닉030 : 탈퇴 회원과 지속 회원의 차이를 파악하기
테크닉023에서 집계한 탈퇴 회원과 지속 회원의 수는 각각 1,350명, 2,840명이다. 탈퇴 회원과 지속 회원을 나눠서 describe로 비교해보자.
# 탈퇴 회원과 지속 회원을 나눠서 describe로 비교
customer_end = customer_join.loc[customer_join['is_deleted'] == 1]
customer_end.describe()
customer_stay = customer_join.loc[customer_join['is_deleted'] == 0]
customer_stay.describe()
결과를 확인해 보면, 탈퇴 회원의 매월 이용 횟수의 평균값, 중앙값, 최댓값, 최솟값은 모두 지속 회원보다 작다. 특히 평균값과 중앙값은 1.5배 정도 차이가 나는 것을 알 수 있다. 반면에 매월 최대 이용 횟수의 평균값은 지속 회원이 높기는 하지만, 탈퇴 회원도 6.4로 높은 편이다. routine_flg의 평균값은 차이가 크게 난다. 지속 회원은 0.98로 많은 회원이 정기적으로 이용하고 있다는 것을 알 수 있지만, 탈퇴 회원은 0.45로 거의 절반은 랜덤하게 이용하고 있다고 생각할 수 있다.
이렇게 행동 데이터를 풀어가면 탈퇴 회원과의 차이를 확인할 수 있으며, 기간을 줄이거나 회원의 재적 기간별로 조사해 나가면 더 많은 정보를 확인할 수 있을 것이다.
'파이썬' 카테고리의 다른 글
| 파이썬 데이터 분석 실무 테크닉 100 -머신러닝(2) (0) | 2021.06.01 |
|---|---|
| [파이썬 실습] Logistic Regression 실습 (0) | 2021.05.31 |
| [파이썬 실습] Linear Regression 실습 (0) | 2021.05.28 |
| 파이썬 데이터 분석 실무 테크닉 100 -데이터 가공(2) (0) | 2021.05.25 |
| 파이썬 데이터 분석 실무 테크닉 100 - 데이터 가공 (0) | 2021.03.13 |