데이터 분석을 위해 현장감각을 익히고 자연스럽게 진입할 수 있는 능력을 기르기 위해 이 책을 구매했다.

1부 데이터 가공
1장 웹에서 주문 수를 분석하는 테크닉 10
분석 목표 : 쇼핑몰 사이트의 데이터를 통해 상품 주문 수의 추세를 분석함으로써 판매량 개선의 방향을 찾는 것
전제조건
- 쇼핑몰 사이트의 데이터를 다룸
- 주요 품목은 컴퓨터
- 가격대별로 5개의 상품 존재
| No. | 파일 이름 | 개요 |
| 1 | customer_master.csv | 고객 데이터, 이름, 성별 등 |
| 2 | item_master.csv | 취급하는 상품 데이터, 상품명, 가격 등 |
| 3-1 | transaction_1.csv | 구매내역 데이터 |
| 3-2 | transaction_2.csv | 3-1과 연결된 구매내역 분할 데이터 |
| 4-1 | transaction_detail_1.csv | 구매내역 상세 데이터 |
| 4-2 | transaction_detail_2.csv | 4-1과 연결된 분할 데이터 |
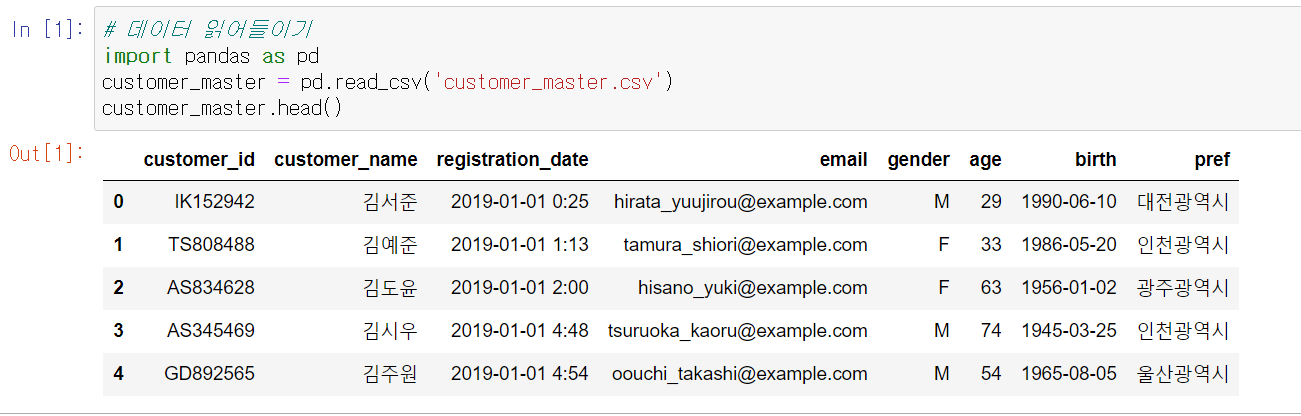
테크닉 001. 데이터 읽기
import pandas as pd
customer_master = pd.read_csv('customer_master.csv')
customer_master.head()
결과값은 다음과 같다
똑같이 다른 데이터도 불러온다.
item_master = pd.read_csv('item_master_csv')
item_master.head()
transaction_1 = pd.read_csv('transaction_1.csv')
transaction_1.head()
transaction_detail_1 = pd.read_csv('transaction_detail_1.csv')
transaction_detail_1.head()
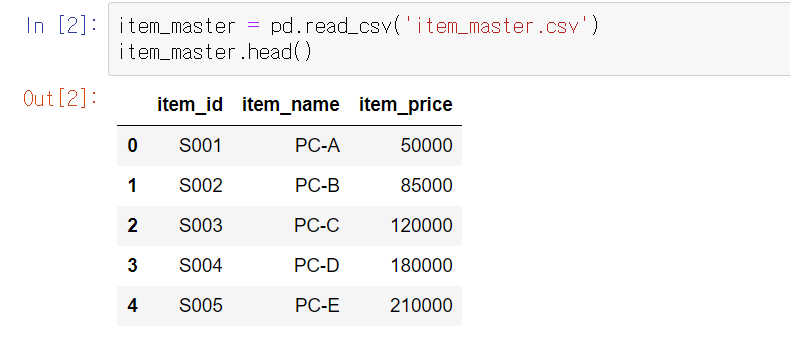
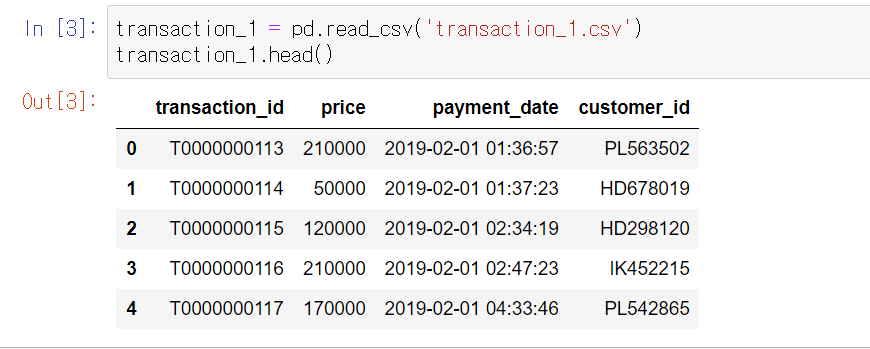
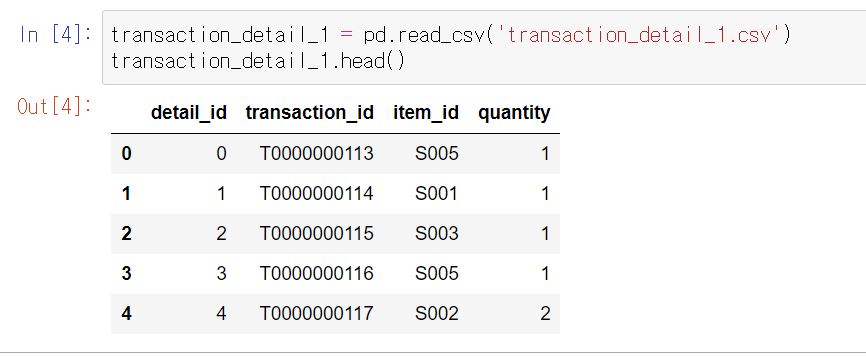
데이터셋 파악
- customer_master에는 고객의 성별과 연령 등의 고객 상세 정보
- item_master에는 상품명과 상품 단가 정보
- transaction에는 언제 누가 얼마나 구매했는지의 정보
- transaction_detail 데이터에는 구입한 상품과 수량 정보
쇼핑몰 사이트의 경우에 당연히 매출과 연관이 있기 때문에 매출 관련 데이터인 transaction_detail을 기준으로 생각해 보자.
transaction_detail 기준으로 생각할 경우 크게 2가의 데이터 가공이 필요하다.
transaction_detail의 경우 1과 2로 분할되어 있기 때문에 결합을 해야 한다.
테크닉 002. 데이터를 결합(유니언) 해 보자
transaction_2 = pd.read_csv('transaction_2.csv')
transaction = pd.concat([transaction_1, transaction_2], ignore_index = True # 기존 인덱스 무시)
transaction.head()
print(len(transaction_1))
print(len(transaction_2))
print(len(transaction))
5000과 1786을 더하면 6786이 되므로 유니언 된 것을 확인할 수 있다. 마찬가지로 transaction_detail도 유니언 한다.
transaction_detail_2 = pd.read_csv('transaction_detail_2.csv')
transaction_detail = pd.concat([transaction_detail_1, transaction_detail_2], ignore_index = True)
transaction_detail.head()
테크닉 003. 매출 데이터끼리 결합(조인) 해 보자
데이터를 조인할 때는 기준이 되는 데이터를 정확하게 결정하고, 어떤 칼럼을 키로 조인할지 생각해야 한다. 가장 상세한 데이터인 transaction_detail을 기준 데이터로 정하고, 매출 데이터를 조인할 때 부족한 데이터 칼럼이 무엇인가와 공통되는 데이터 칼럼은 무엇인가를 생각해야 한다.
추가할 데이터는 transaction의 payment_date, customer_id이다.
join_data = pd.merge(transaction_detail, transaction[['transaction_id', 'payment_date', 'customer_id']], on = 'transaction_id', how = 'left') # 레프트 조인
join_data.head()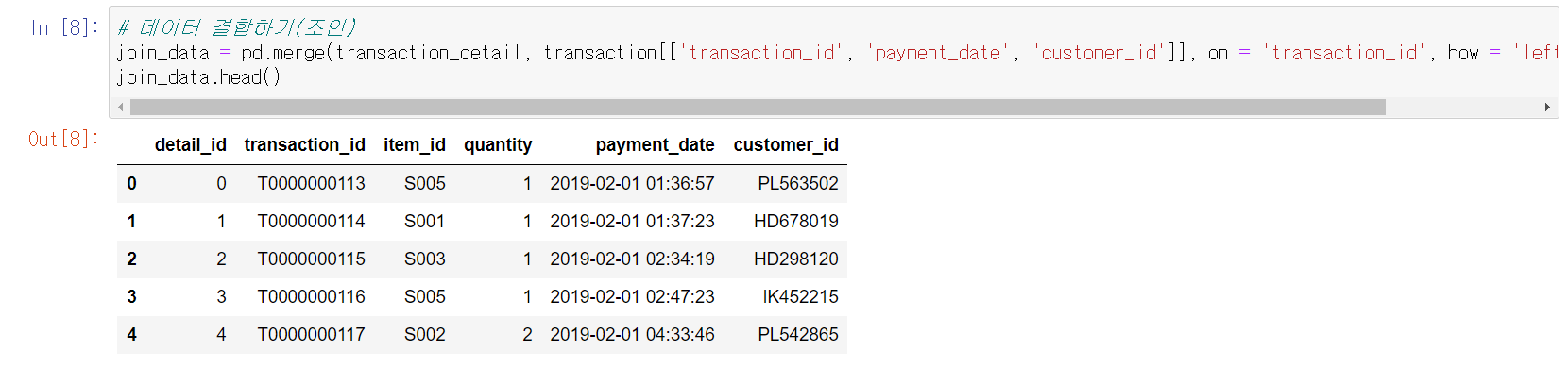
성공적으로 조인이 되었다면 데이터 개수를 살펴본다.
print(len(transaction_detail))
print(len(transaction))
print(len(join_data))
테크닉 004. 마스터 데이터를 결합(조인) 해 보자
부족한 데이터는 무엇인가, 공통 칼럼은 무엇인가를 생각하자. 추가할 데이터는 customer_master와 item_master에 포함된 데이터이다.
join_data = pd.merge(join_data, customer_master, on = 'customer_id', how = 'left')
join_data = pd.merge(join_data, item_master, on = 'item_id', how = 'left')
join_data.head()
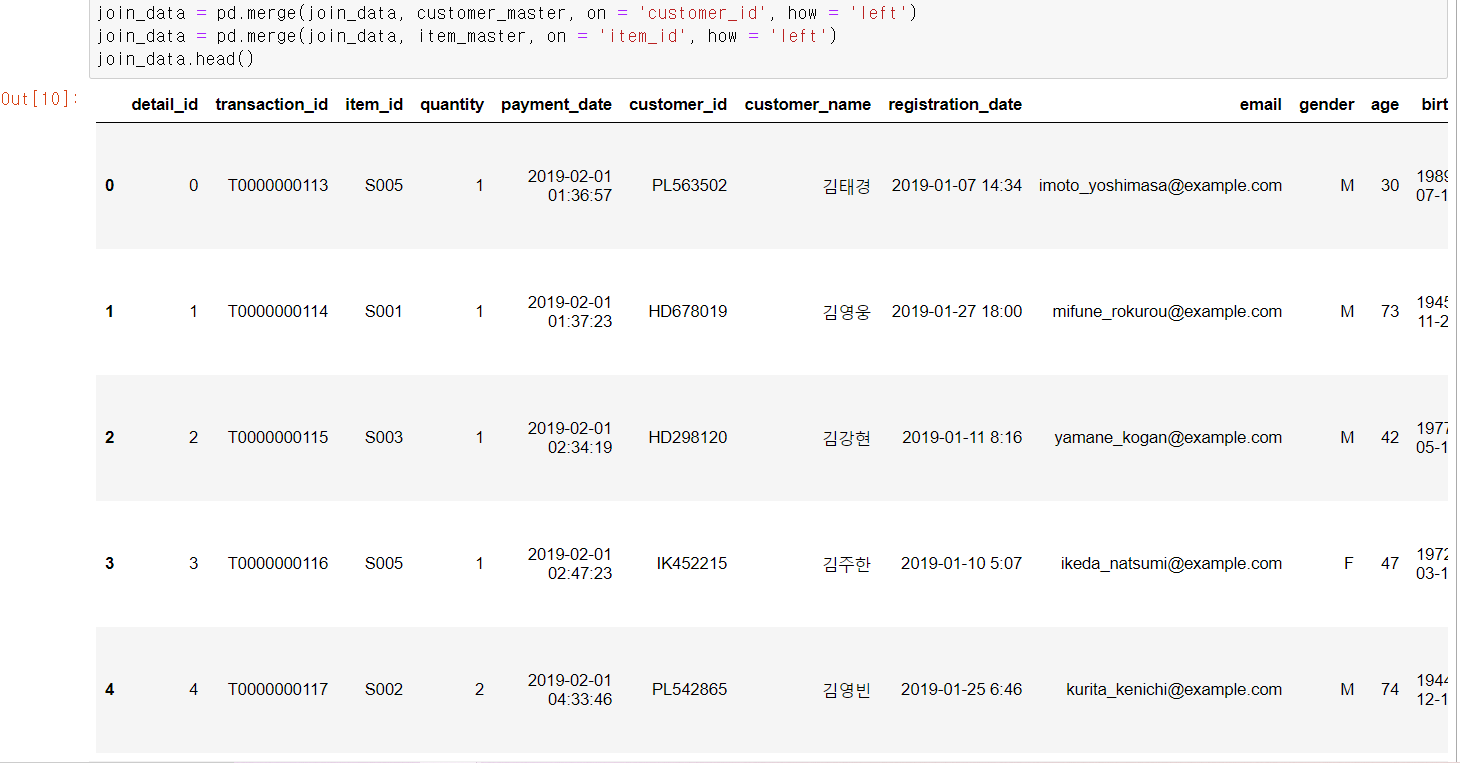
고객 정보와 상품 정보가 추가된 것을 확인할 수 있다. 하지만 결합의 영향으로 매출(price)이 사라졌기 때문에 다시 계산해야 한다.
테크닉 005. 필요한 데이터 칼럼 만들기
join_data['price'] = join_data['quantity'] * join_data['item_price']
join_data[['quantity', 'item_price', 'price']].head()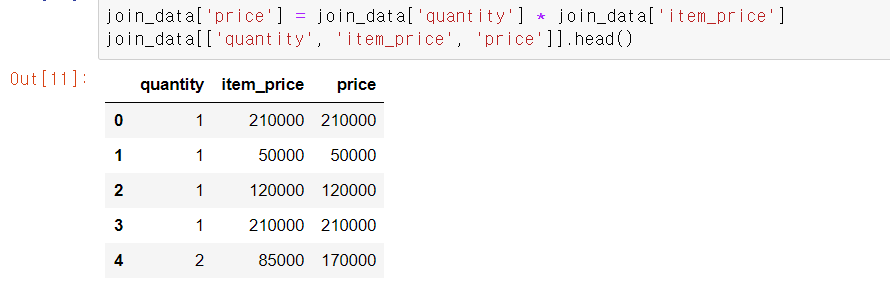
결과에서 quantity가 2인 행의 price가 단가의 2배인 것으로 봐서 제대로 계산된 것을 확인할 수 있다.
테크닉 006. 데이터를 검산하자
print(join_data['price'].sum())
print(transaction['price'].sum())
join_data['price'].sum() == transaction['price'].sum()
위의 두 개의 결과를 보면 971135000이 2개 표시되며 완전히 일치하는 것을 확인할 수 있다. 또한 데이터 검산에도 True라는 값이 출력되었기 때문에 틀린 데이터가 없는 걸로 확인되었다.
테크닉 007. 각종 통계량을 파악하자
데이터 분석을 진행할 때 크게 2가지 숫자를 파악해야 한다. 첫 번째는 결손치의 개수, 두 번째는 전체를 파악할 수 있는 숫자 감이다.
데이터에는 항상 결손치가 포함될 가능성이 있다. 결손치의 계산이나 머신러닝의 결과에 큰 영향을 미치기 때문에 숫자를 파악해두고 제거하거나 보관해야 한다.
# 각종 통계량 파악하기
join_data.isnull().sum()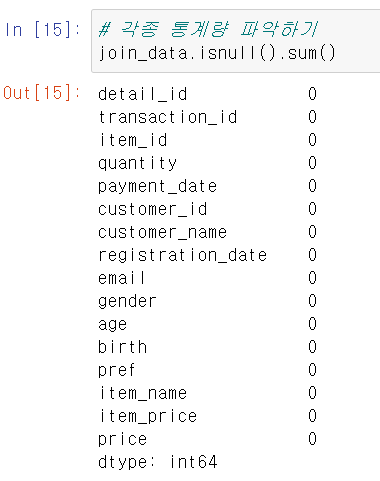
# 각종 통계량 출력
join_data.describe()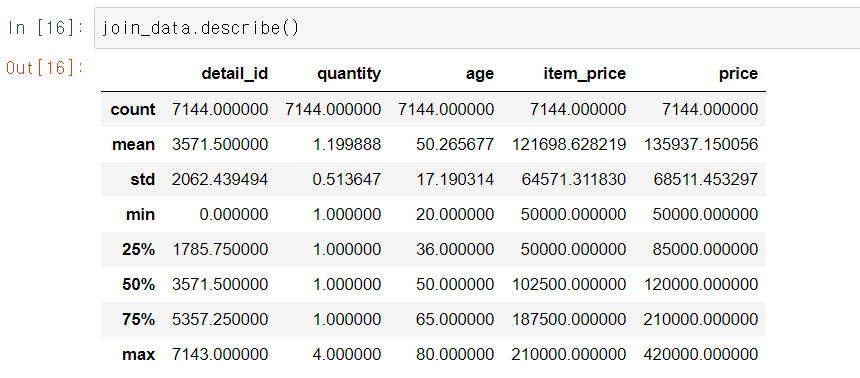
print(join_data['payment_date'].min())
print(join_data['payment_date'].max())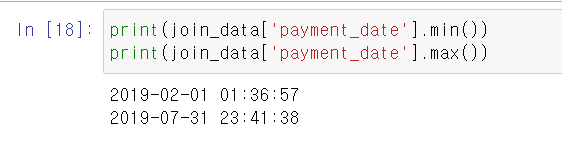
위의 코드를 실행하면 데이터의 기간이 2019년 2월 1일부터 2019년 7월 31일까지임을 알 수 있다.
테크닉 008. 월별로 데이터를 집계해 보자
pandas의 dt를 사용해 년, 월을 추출한다. 또한, strftime을 사용해 연월을 작성한다.
join_data['payment_date'] = pd.to_datetime(join_data['payment_date']) # datetime으로 변환
join_data['payment_month'] = join_data['payment_date'].dt.strftime('%Y%m') # payment_month 생성, strftie을 사용해 연월 작성
join_data[['payment_date', 'payment_month']].head()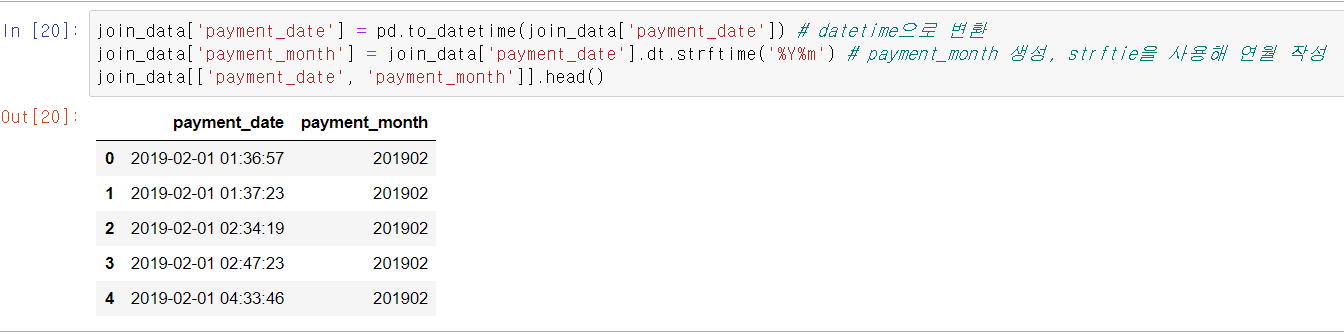
위의 코드를 실행하면 집계를 할 수 있다.
join_data.groupby('payment_month').sum()['price']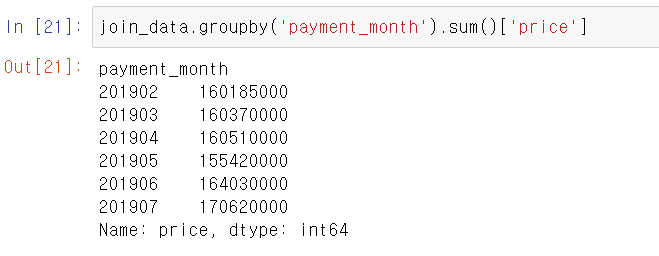
groupby는 집계하고 싶은 칼럼과 집계 방법을 기술한다. 결과를 보면 5월은 매출이 조금 내려갔지만, 6월과 7월은 회복했고 반년 동안 가장 매출이 높은 달은 7월이다. 한 달에 대략 1억 6천만 원 정도의 매출이 나오며, 연간 20억 원 정도의 매출이 기대된다.
테크닉 009. 월별, 상품별로 데이터를 집계해 보자
# 월별, 상품별로 데이터 집계하기
join_data.groupby(['payment_month', 'item_name']).sum()[['price', 'quantity']]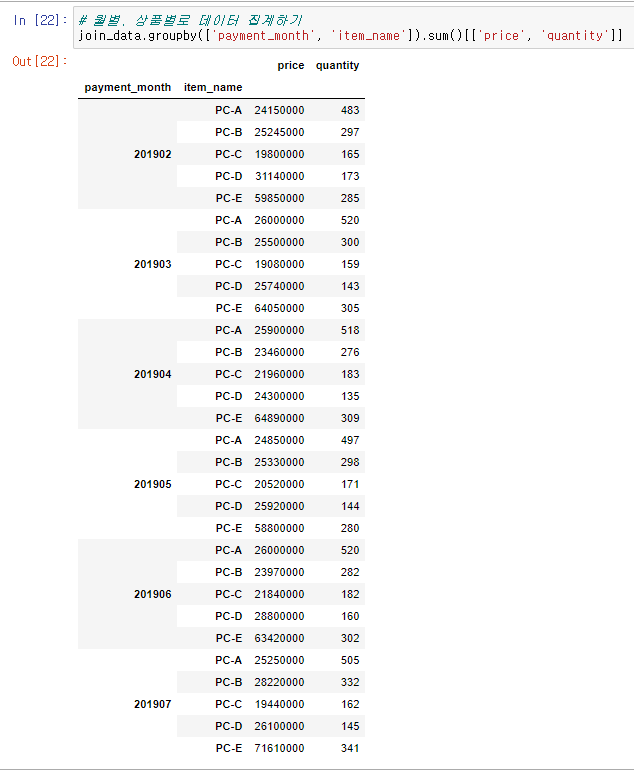
월별, 상품별로 price와 quantity의 집계 결과가 표시된다. 출력 결과가 직관적으로 이해하기 어려우니 pivot_table 함수를 사용해 다시 집계해 보자.
pd.pivot_table(join_data, index = 'item_name', columns = 'payment_month', values=['price', 'quantity'], aggfunc = 'sum')
## pivot_table = 행과 칼럼 지정, value = 집계하고 싶은 칼럼, aggfunc = 집계방법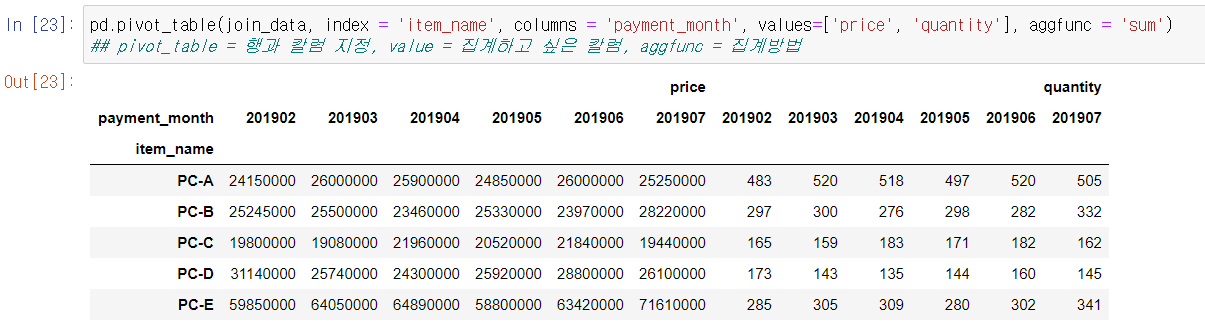
pivot_table 함수는 행과 칼럼을 저장할 수 있다. 행에는 상품명, 칼럼에는 월이 오게 index와 columns로 지정한다. values에는 집계하고 싶은 칼럼, aggfunc에는 집계 방법을 지정한다.
매출의 합계는 PC-E가 가장 높지만, 수량에서는 가장 싼 PC-A가 많다. 상품별로 보면, 5월은 PC-B와 PC-D가 증가했지만, 큰 매출을 차지하는 PC-E의 매출이 많이 감소한 것이 매출 하락의 영향을 미친 것 같다.
테크닉 010. 상품별 매출 추이를 가시화해 보자
pivot_table을 이용해 데이터를 집계한다.
# 상품별 매출 추이 가시화
graph_data = pd.pivot_table(join_data, index = 'payment_month', columns = 'item_name', values = 'price', aggfunc = 'sum')
graph_data.head()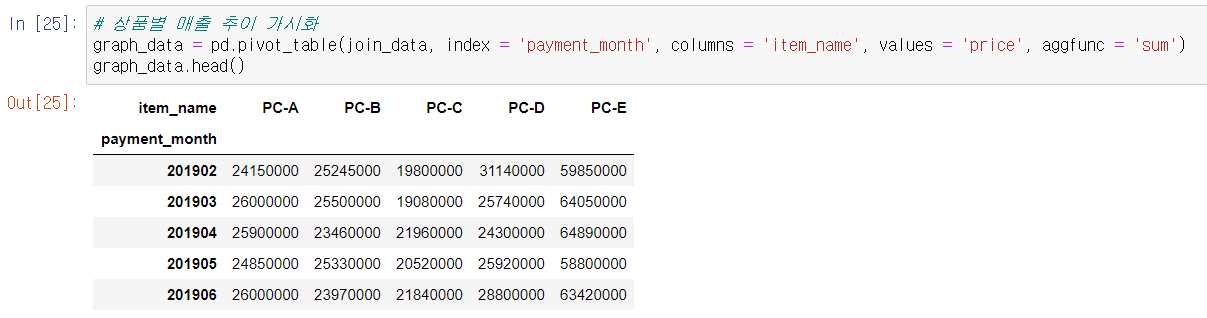
matplotlib을 이용해서 그래프를 그린다.
# 그래프 그리기
import matplotlib.pyplot as plt
%matplotlib inline
plt.plot(list(graph_data.index), graph_data['PC-A'], label = 'PC-A')
plt.plot(list(graph_data.index), graph_data['PC-B'], label = 'PC-B')
plt.plot(list(graph_data.index), graph_data['PC-C'], label = 'PC-C')
plt.plot(list(graph_data.index), graph_data['PC-D'], label = 'PC-D')
plt.plot(list(graph_data.index), graph_data['PC-E'], label = 'PC-E')
plt.legend()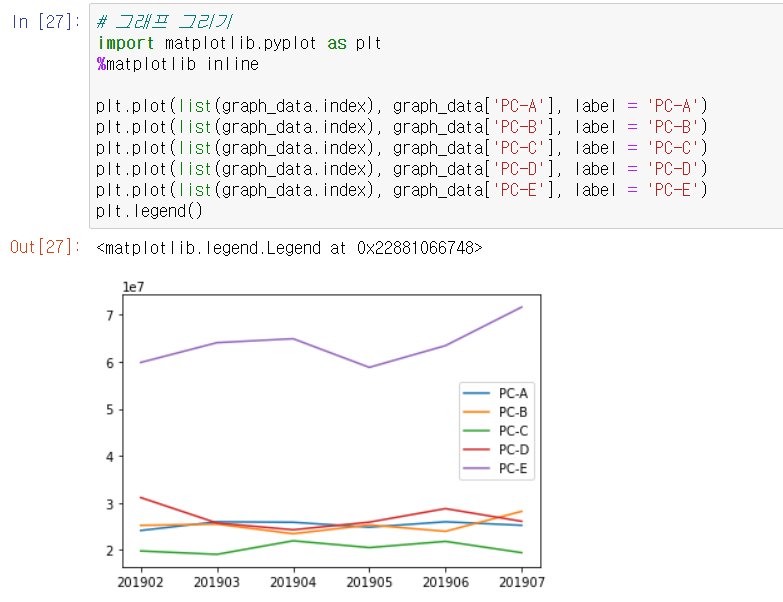
그래프를 보면 PC-E가 매출을 견인하는 기종이라는 점과 매출 추이를 파악할 수 있다.
'파이썬' 카테고리의 다른 글
| 파이썬 데이터 분석 실무 테크닉 100 -머신러닝(2) (0) | 2021.06.01 |
|---|---|
| [파이썬 실습] Logistic Regression 실습 (0) | 2021.05.31 |
| [파이썬 실습] Linear Regression 실습 (0) | 2021.05.28 |
| 파이썬 데이터 분석 실무 테크닉 100 -머신러닝(1) (0) | 2021.05.26 |
| 파이썬 데이터 분석 실무 테크닉 100 -데이터 가공(2) (0) | 2021.05.25 |