엿보기(Peeky)
seq2seq의 두 번째 개선은 엿보기(Peeky)이다. Encoder 동작은 입력 문장(문제 문장)을 고정 길이 벡터 h로 변환한다. 이때 h 안에는 Decoder에게 필요한 정보가 모두 담겨 있다. 그러나 현재의 seq2seq는 아래 그림과 같이 최초 시각의 LSTM 계층만이 벡터 h를 이용하고 있다.
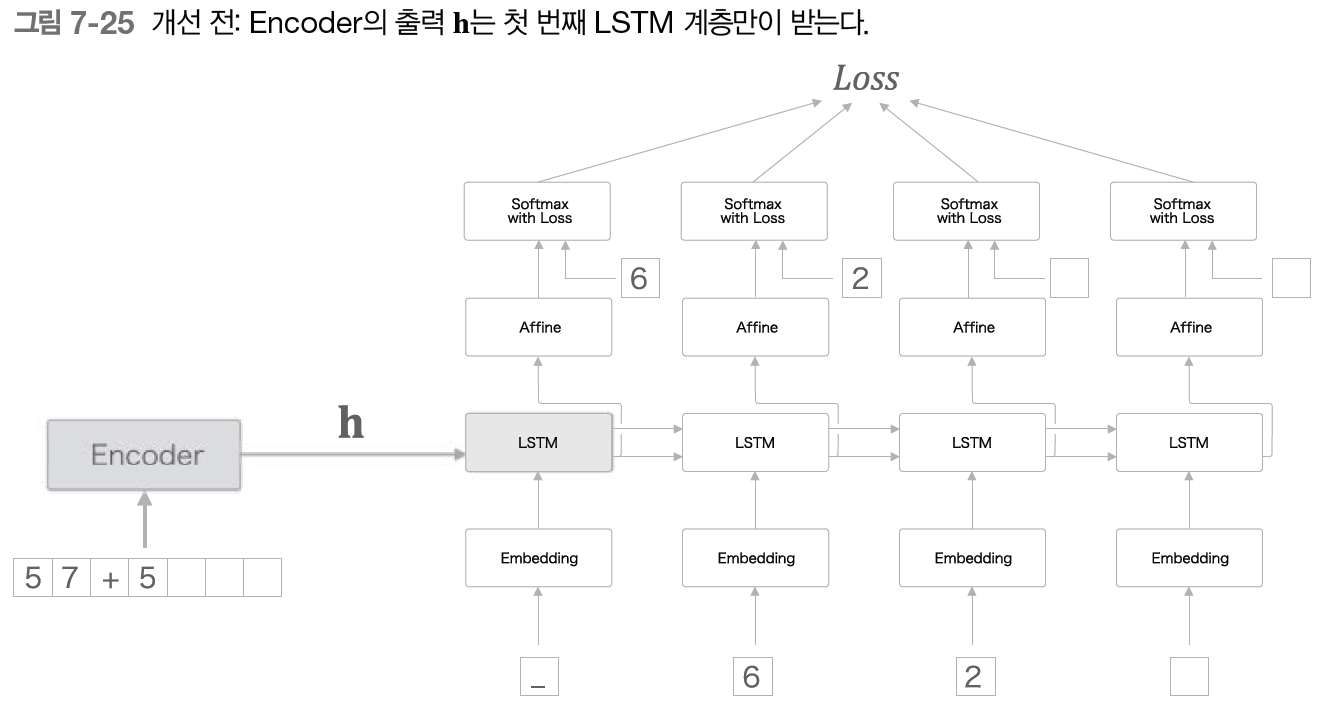
이 중요한 정보인 h를 더 활용할 수는 없을까?
여기서 두 번째 개선안으로 중요한 정보가 담긴 Encoder의 출력 h를 Decoder의 다른 계층에게도 전해주는 것이다.
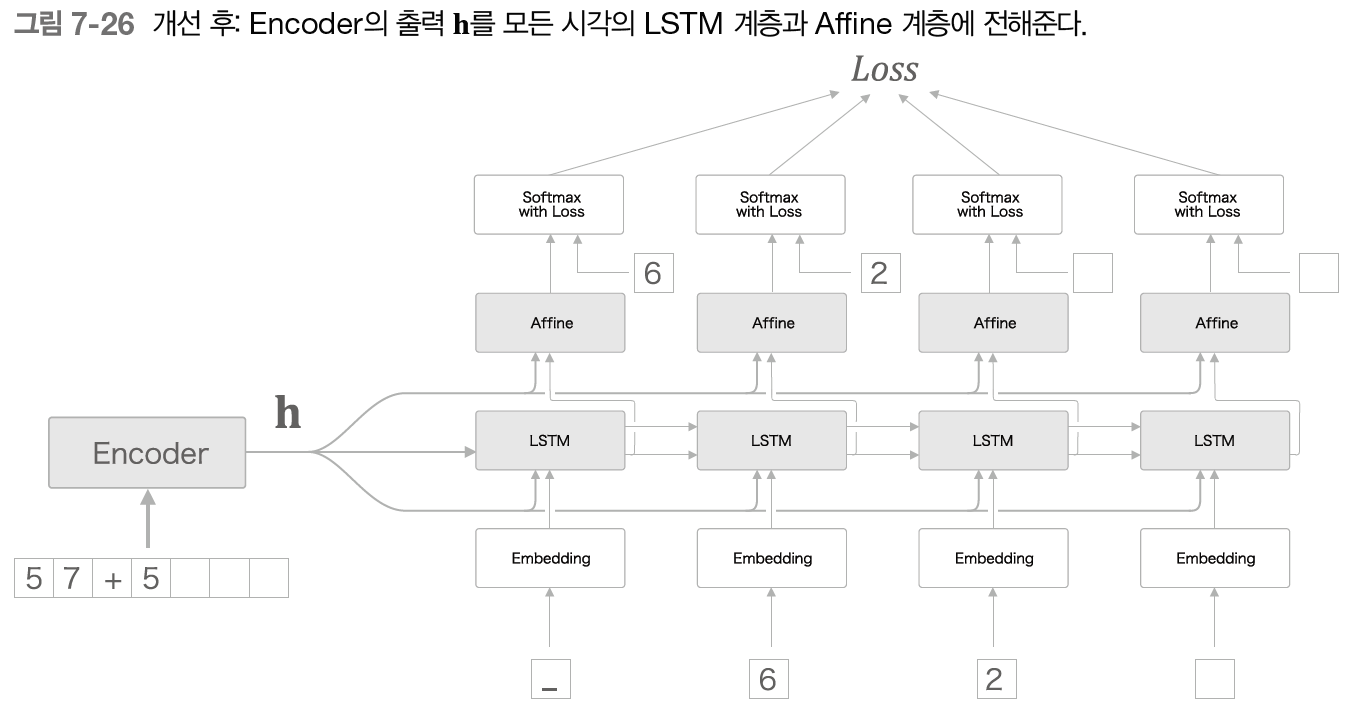
위의 그림과 같이 모든 시각의 Affine 계층과 LSTM 계층에 Encoder의 출력 h를 전해준다. 개선 전 그림과 비교해보면 기존에는 하나의 LSTM만이 소유하던 중요 정보 h를 여러 계층이 공유함을 알 수 있다. 이는 집단지성에 비유할 수 있다.
중요한 정보를 한 사람이 독점하는 게 아니라 많은 사람과 공유한다면 더 올바른 결정을 내릴 가능성이 커질 것이다.
개선 후 그림에서는 LSTM 계층과 Affine 계층에 입력되는 벡터가 2개씩이 되었다. 이는 실제로 두 벡터가 연결된 것을 의미한다. 따라서 앞의 그림은 두 벡터를 연결시키는 concat 노드를 이용해 아래 그림처럼 그려야 정확한 계산 그래프이다.
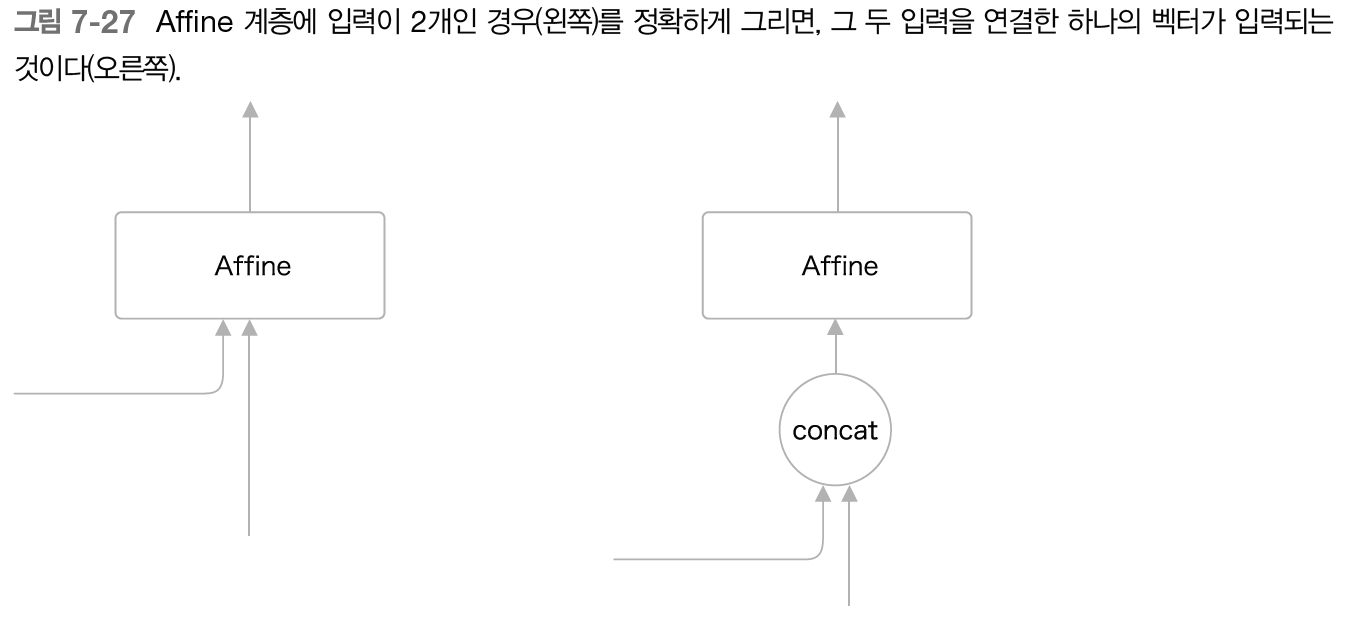
이제 Peeky Decoder 클래스의 구현을 알아보자.
class PeekyDecoder:
def __init__(self, vocab_size, wordvec_size, hidden_size):
V, D, H = vocab_size, wordvec_size, hidden_size
rn = np.random.randn
embed_W = (rn(V, D) / 100).astype('f')
lstm_Wx = (rn(H + D, 4 * H) / np.sqrt(H + D)).astype('f')
lstm_Wh = (rn(H, 4 * H) / np.sqrt(H)).astype('f')
lstm_b = np.zeros(4 * H).astype('f')
affine_W = (rn(H + H, V) / np.sqrt(H + H)).astype('f')
affine_b = np.zeros(V).astype('f')
self.embed = TimeEmbedding(embed_W)
self.lstm = TimeLSTM(lstm_Wx, lstm_Wh, lstm_b, stateful = True)
self.affine = TimeAffine(affine_W, affine_b)
self.params, self.grads = [], []
for layer in (self.embed, self.lstm, self.affine):
self.params += layer.params
self.grads += layer.grads
self.cache = None
def forward(self, xs, h):
N, T = xs.shape
N, H = h.shape
self.lstm.set_state(h)
out = self.embed.forward(xs)
hs = np.repeat(h, T, axis = 0).reshape(N, T, H)
out = np.concatenate((hs, out), axis = 2)
out = self.lstm.forward(out)
out = np.concatenate((hs, out), axis = 2)
score = self.affine.forward(out)
self.cache = H
return score
def backward(self, dscore):
H = self.cache
dout = self.affine.backward(dscore)
dout, dhs0 = dout[:, :, H:], dout[:, :, :H]
dout = self.lstm.backward(dout)
dembed, dhs1 = dout[:, :, H:], dout[:, :, :H]
self.embed.backward(dembed)
dhs = dhs0 + dhs1
dh = self.lstm.dh + np.sum(dhs, axis=1)
return dh
def generate(self, h, start_id, sample_size):
sampled = []
char_id = start_id
self.lstm.set_state(h)
H = h.shape[1]
peeky_h = h.reshape(1, 1, H)
for _ in range(sample_size):
x = np.array([char_id]).reshape((1, 1))
out = self.embed.forward(x)
out = np.concatenate((peeky_h, out), axis=2)
out = self.lstm.forward(out)
out = np.concatenate((peeky_h, out), axis=2)
score = self.affine.forward(out)
char_id = np.argmax(score.flatten())
sampled.append(char_id)
return sampledPeekyDecoder의 초기화는 앞에 구현했던 Decoder와 거의 같다. 다른 점은 LSTM 계층의 가중치와 Affine 계층의 가중치의 형상뿐이다. 이번 구현에서는 Encoder가 인코딩한 벡터도 입력되기 떄문에 가중치 매개변수의 형상이 그만큼 커진다.
forward() 메서드는 h를 np.repeat()로 시계열만큼 복제해 hs에 저장한다. 다음 np.concatenate()를 이용해 그 hs와 Embedding 계층의 출력을 연결하고, 이를 LSTM 계층에 입력한다.
class PeekySeq2seq(seq2seq):
def __init__(self, vocab_size, wordvec_size, hidden_size):
V, D, H = vocab_size, wordvec_size, hidden_size
self.encoder = Encoder(V, D, H)
self.decoder = PeekyDecoder(V, D, H)
self.softmax = TimeSoftmaxWithLoss()
self.params = self.encoder.params + self.decoder.params
self.grads = self.encoder.grads + self.decoder.grads마지막으로 PeekySeq2seq 클래스이다. Decoder 계층에서 차이를 보인다.
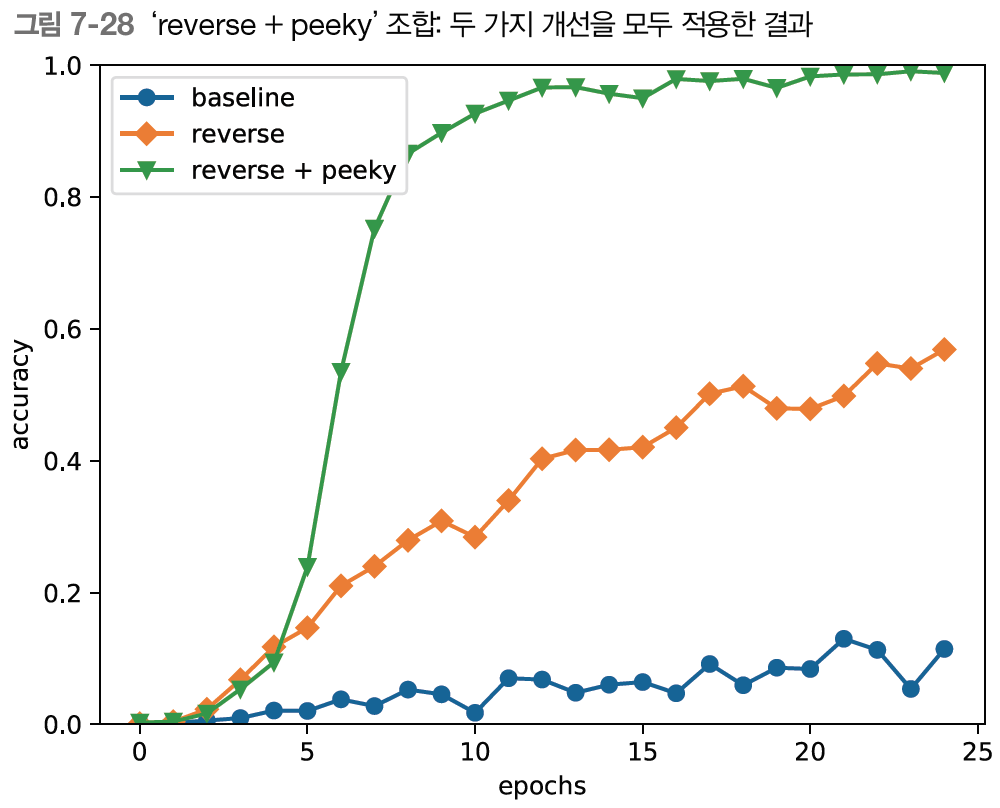
최종 결과 그래프로 보면 Peeky를 적용한 seq2seq의 결과가 월등히 좋아진 것을 확인할 수 있다.
10 에폭을 넘어가면서 정답률이 이미 90%를 넘고 최종적으로 100%에 가까워지는 것을 볼 수 있다.
지금까지 seq2seq의 개선을 공부해봤다. 다음으론 더 큰 개선을 통해 seq2seq를 극대화시킬 예정이다. Peeky를 이용하게 되면 구현한 신경망은 가중치 매개변수가 커져서 계산량도 늘어난다. 또한, seq2seq의 정확도는 하이퍼파라미터에 영향을 크게 받는다.
'딥러닝' 카테고리의 다른 글
| 밑바닥부터 시작하는 딥러닝 - 어텐션(2) (0) | 2021.11.11 |
|---|---|
| 밑바닥부터 시작하는 딥러닝 - 어텐션(1) (0) | 2021.11.10 |
| 밑바닥부터 시작하는 딥러닝 - seq2seq(2) (0) | 2021.11.05 |
| 밑바닥부터 시작하는 딥러닝 - seq2seq(1) (0) | 2021.11.04 |
| 밑바닥부터 시작하는 딥러닝 - RNN을 사용한 문장 생성 (0) | 2021.11.03 |