이번 글부터는 자연어 처리에 대해 기초적인 것들을 알아볼 것이다.
한국어와 영어 등 우리가 평소에 쓰는 말을 자연어(Natural Language)라고 한다.
자연어 처리(Natural Language Processing)를 문자 그대로 해석하면 '자연어를 처리하는 분야'이고 '우리의 말을 컴퓨터에게 이해시키기 위한 기술'이라고 볼 수 있다.
그래서 자연어 처리가 추구하는 목표는 사람의 말을 컴퓨터가 이해하도록 만들어서, 컴퓨터가 우리에게 도움이 되는 일을 수행하게 하는 것이다.
단어의 의미
단어는 의미의 최소 단위이다. 자연어를 컴퓨터에게 이해시키는 데는 무엇보다 '단어의 의미'를 이해시키는 게 중요하다.
컴퓨터의 단어의 의미를 잘 파악하는 표현 방법에는 세 가지가 있다.
- 시소러스를 활용한 기법
- 통계 기반 기법
- 추론 기반 기법
시소러스
시소러스란 유의어 사전으로, '뜻이 같은 단어(동의어)'나 '뜻이 비슷한 단어(유의어)'가 한 그룹으로 분류되어 있는 것을 말한다.

위의 그림처럼 모든 단어에 대한 유의어 집합을 만든 다음, 단어들의 관계를 그래프로 표현하여 단어 사이의 연결을 정의할 수 있다.
WordNet
자연어 처리 분야에서 가장 유명한 시소러스는 WordNet이다. WordNet은 프린스턴 대학교에서 1985년부터 구축하기 시작한 전통있는 시소러스로, 지금까지 많은 연구와 다양한 자연어 처리 애플리케이션에서 활용되고 있다.
WordNet을 사용하면 유의어를 얻거나 '단어 네트워크'를 이용할 수 있다.
시소러스의 문제점
사람이 수작업으로 레이블링하는 방식에는 크나큰 결점이 존재한다.
- 시대 변화에 대응하기 어렵다.
- 사람을 쓰는 비용은 크다.
- 단어의 미묘한 차이를 표현할 수 없다.
이처럼 시소러스를 사용하는 기법에는 문제점이 많이 있다.
이 문제를 피하기 위해, '통계 기반 기법'과 신경망을 사용한 '추론 기반 기법'을 뒤에서 알아볼 것이다.
통계 기반 기법
통계 기반 기법에선 말뭉치(corpus)를 이용한다. 말뭉치란 대량의 텍스트 데이터를 뜻한다.
수집된 텍스트 데이터가 아닌 자연어 처리 연구나 애플리케이션을 염두에 두고 수집된 텍스트 데이터를 일반적으로 '말뭉치'라고 한다.
통계 기반 기법의 목표는 사람의 지식으로 가득한 말뭉치에서 자동으로, 그리고 효율적으로 그 핵심을 추출하는 것이다.
text = 'You say goodbye and I say hello.'
text = text.lower()
text = text.replace('.', ' .')
words = text.split(' ')
words
텍스트를 lower() 메서드를 사용해 모든 문자를 소문자로 변환한다. 문장 첫머리의 대문자로 시작하는 단어도 소문자 단어와 똑같이 취급하기 위한 조치이다.
그리고 split('') 메서드를 호출해 공백을 기준으로 분할한다. 여기서는 문장 끝의 마침표를 고려해 마침표 앞에 공백을 삽입한 다음 분할을 수행했다.
단어 단위로 분할되어 다루기가 쉬워졌지만, 단어를 텍스트 그대로 조작하기엔 여러 면에서 불편하다.
그래서 단어에 ID를 부여하고, ID의 리스트로 이용할 수 있도록 한 번 더 처리한다.
word_to_id = {}
id_to_word = {}
for word in words:
if word not in word_to_id:
new_id = len(word_to_id)
word_to_id[word] = new_id
id_to_word[new_id] = word단어 ID에서 단어로의 변환은 id_to_word가 담당하고, 단어에서 단어 ID로의 변환은 word_to_id가 담당한다.
단어 단위로 분할된 words의 각 원소를 처음부터 하나씩 살펴보면서, 단어가 word_to_id에 들어 있지 않으면 word_to_id와 id_to_word 각각에 새로운 ID와 단어를 추가한다.
또한 추가 시점의 딕셔너리 길이가 새로운 단어의 ID로 설정되기 때문에 ID는 0, 1, 2,... 식으로 증가한다.
위의 코드를 끝으로 말뭉치를 이용하기 위한 준비는 끝마쳤다. 이상의 처리를 모아 함수로 구현해놓자.
def preprocess(text):
text = text.lower()
text = text.replace('.', ' .')
words = text.split(' ')
word_to_id = {}
id_to_word = {}
for word in words:
if word not in word_to_id:
new_id = len(word_to_id)
word_to_id[word] = new_id
id_to_word[new_id] = word
corpus = np.array([word_to_id[w] for w in words])
return corpus, word_to_id, id_to_word단어의 분산 표현
'색'을 벡터로 표현하듯 '단어'도 벡터로 표현이 가능하다. 이를 자연어 처리 분야에서는 단어의 분산 표현이라고 한다.
분포 가설
분포 가설이란 '단어의 의미는 주변 단어에 의해 형성된다.', 단어를 벡터로 표현하는 최근 연구도 대부분 이 가설에 기초한다. 분포 가설은 단어 자체에는 의미가 없고, 그 단어가 사용된 '맥락'이 의미를 형성한다는 것이다.

동시발생 행렬
분포 가설에 기초해 단어를 벡터로 나타내는 방법을 생각해보자. 주변 단어를 '세어 보는' 방법이 떠오를 것이다.
어떤 단어에 주목했을 때, 그 주변에 어떤 단어가 몇 번이나 등장하는지를 세어 집계하는 방법이다.

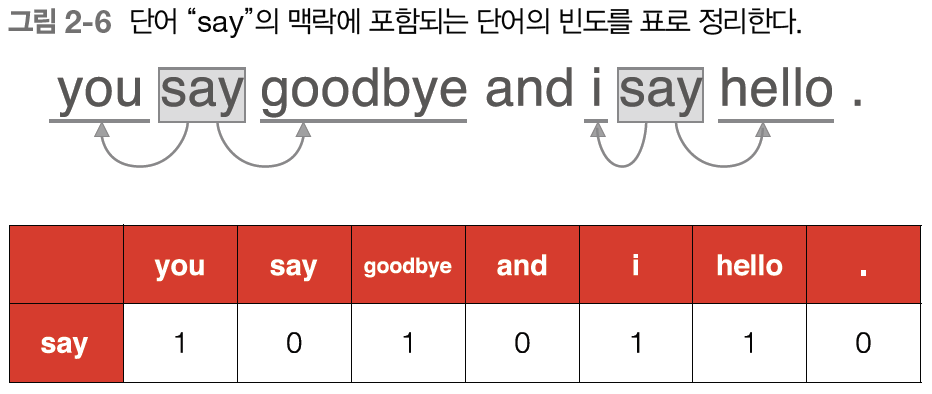
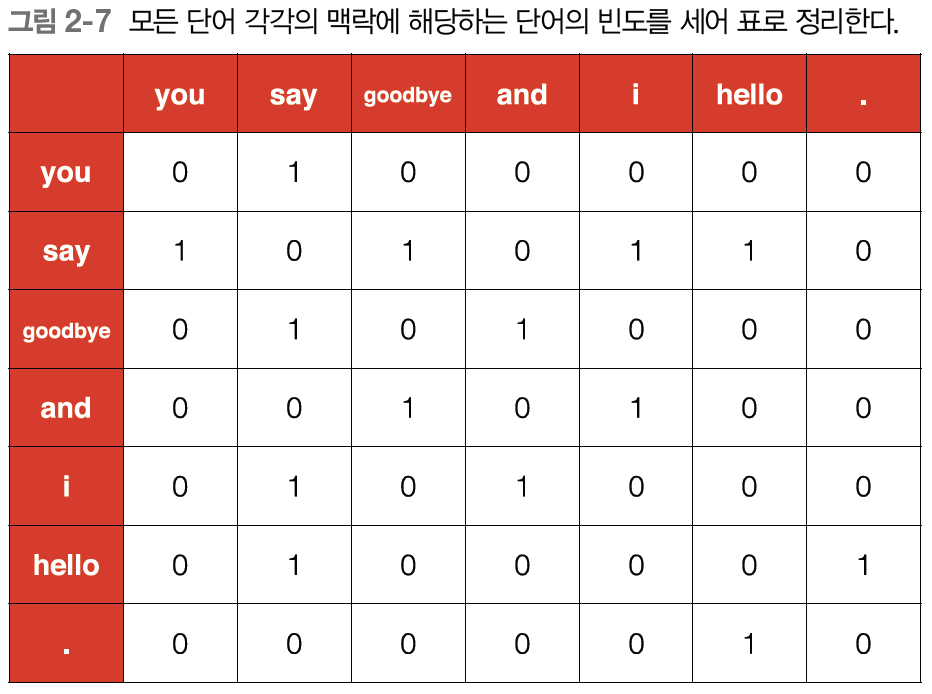
위의 그림이 동시발생하는 단어를 표에 정리한 것이다. 이 표의 각 행은 해당 단어를 표현한 벡터가 된다. 이 표가 행렬의 형태를 띤다는 뜻에서 동시발생 행렬이라고 한다.
그렇다면 말뭉치로부터 동시발생행렬을 만들어주는 함수를 구현해보자.
def create_co_matrix(coupus, vocab_size, window_size = 1):
corpus_size = len(corpus)
co_matrix = np.zeros((vocab_size, vocab_size), dtype = np.int32)
for idx, word_id in enumerate(corpus):
for i in range(1, window_size + 1):
left_idx = idx - i
right_idx = idx + i
if left_idx >= 0:
left_word_id = corpus[left_idx]
co_matrix[word_id, left_word_id] += 1
if right_idx < corpus_size:
right_word_id = corpus[right_idx]
co_matrix[word_id, right_word_id] += 1
return co_matrix먼저 co_matrix를 0으로 채워진 2차원 배열로 초기화한다. 그다음 말뭉치의 모든 단어 각각에 대하여 윈도우에 포함된 주변 단어를 세어나간다. 이때 말뭉치의 왼쪽 끝과 오른쪽 끝 경계를 벗어나지 않는지도 확인한다.
이 함수는 말뭉치가 아무리 커지더라도 자동으로 동시발생 행렬을 만들어준다.
'딥러닝' 카테고리의 다른 글
| 밑바닥부터 시작하는 딥러닝 - word2vec (1) (0) | 2021.10.19 |
|---|---|
| 밑바닥부터 시작하는 딥러닝 - 자연어(2) (0) | 2021.10.18 |
| 밑바닥부터 시작하는 딥러닝 - 신경망(4) (0) | 2021.10.15 |
| 밑바닥부터 시작하는 딥러닝 - 신경망(3) (0) | 2021.10.14 |
| 밑바닥부터 시작하는 딥러닝 - 신경망(2) (0) | 2021.10.13 |