2부 머신러닝
5장 회원 탈퇴를 예측하는 테크닉 10
분석 목표 : 의사결정 트리를 통해 탈퇴를 예측하는 흐름 배우기
전제조건
| No. | 파일 이름 | 개요 |
| 1 | use_log.csv | 스포츠 센터의 이용 이력 데이터. 기간은 2018년 4월 ~ 2019년 3월 |
| 2 | customer_master.csv | 2019년 3월 말 시점의 회원 데이터 |
| 3 | class_master.csv | 회원 구분 데이터(종일, 주간, 야간) |
| 4 | campaign_master.csv | 캠페인 구분 데이터(입회비 무료 등) |
| 5 | customer_join.csv | 3장에서 작성한 이용 이력을 포함한 고객 데이터 |
| 6 | use_log_months.csv | 4장에서 작성한 이용 이력을 연월 / 고객별로 집계한 데이터 |
테크닉041 : 데이터를 읽어 들이고 이용 데이터를 수정하자
import pandas as pd
customer = pd.read_csv('customer_join.csv')
uselog_months = pd.read_csv('use_log_months.csv')
다음은 머신러닝을 위해 데이터를 가공한다. 미래를 예측하기 위해 그달과 1개월 전의 이용 이력만으로 데이터를 작성할 것이다. 불과 몇 개월 만에 그만둔 회원도 많기 때문에 과거 6개월분의 데이터를 이용한 예측은 의미가 없다.
따라서 이달과 1개월 전의 이용 횟수를 집계한 데이터를 작성한다.
year_months = list(uselog_months['연월'].unique())
uselog = pd.DataFrame()
for i in range(1, len(year_months)):
tmp = uselog_months.loc[uselog_months['연월'] == year_months[i]]
tmp.rename(columns = {'count' : 'count_0'}, inplace = True)
tmp_before = uselog_months.loc[uselog_months['연월'] == year_months[i - 1]]
del tmp_before['연월']
tmp_before.rename(columns = {'count' : 'count_1'}, inplace = True)
tmp = pd.merge(tmp, tmp_before, on = 'customer_id', how = 'left')
uselog = pd.concat([uselog, tmp], ignore_index = True)
uselog.head()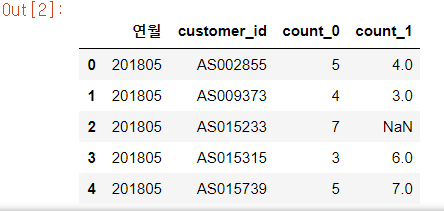
1행에서 연월 컬럼을 리스트화하고 for문을 통해 이번 달과 1개월 전의 이용 횟수를 집계한다. 이번에는 1개월 전 뿐이기 때문에 2018년 5월부터 for문을 반복한다.
테크닉042 : 탈퇴 전월의 탈퇴 고객 데이터를 작성하자
end_date 컬럼의 탈퇴 월이 아닌 탈퇴 전월의 데이터를 작성하는 이유가 뭘까?
탈퇴를 예측하는 목적은 탈퇴를 미연에 방지하는 것이다. 전제 조건으로 이 스포츠 센터는 월말까지 탈퇴 신청을 해야 다음 달 말에 탈퇴할 수 있다. 그렇기 때문에 탈퇴를 미연에 방지할 수 있게 전월의 데이터를 통해 해당 월에 탈퇴 신청을 할 확률을 예측해야 한다.
from dateutil.relativedelta import relativedelta
exit_customer = customer.loc[customer['is_deleted'] == 1]
exit_customer['exit_date'] = None
exit_customer['end_date'] = pd.to_datetime(exit_customer['end_date'])
for i in range(len(exit_customer)):
exit_customer['exit_date'].iloc[i] = exit_customer['end_date'].iloc[i] - relativedelta(months = 1)
exit_customer['연월'] = pd.to_datetime(exit_customer['exit_date']).dt.strftime('%Y%m')
uselog['연월'] = uselog['연월'].astype(str)
exit_uselog = pd.merge(uselog, exit_customer, on = ['customer_id', '연월'], how = 'left')
print(len(uselog))
exit_uselog.head()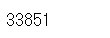

데이터 개수는 uselog를 기준으로 하기 때문에 33851개가 있다. 결합한 데이터는 탈퇴한 회원의 탈퇴 전월의 데이터뿐이므로 결측치가 많이 존재한다. 결측치가 없는 데이터만 남기고 나머지는 제거한다.
exit_uselog = exit_uselog.dropna(subset = ['name'])
print(len(exit_uselog))
print(len(exit_uselog['customer_id'].unique()))
exit_uselog.head()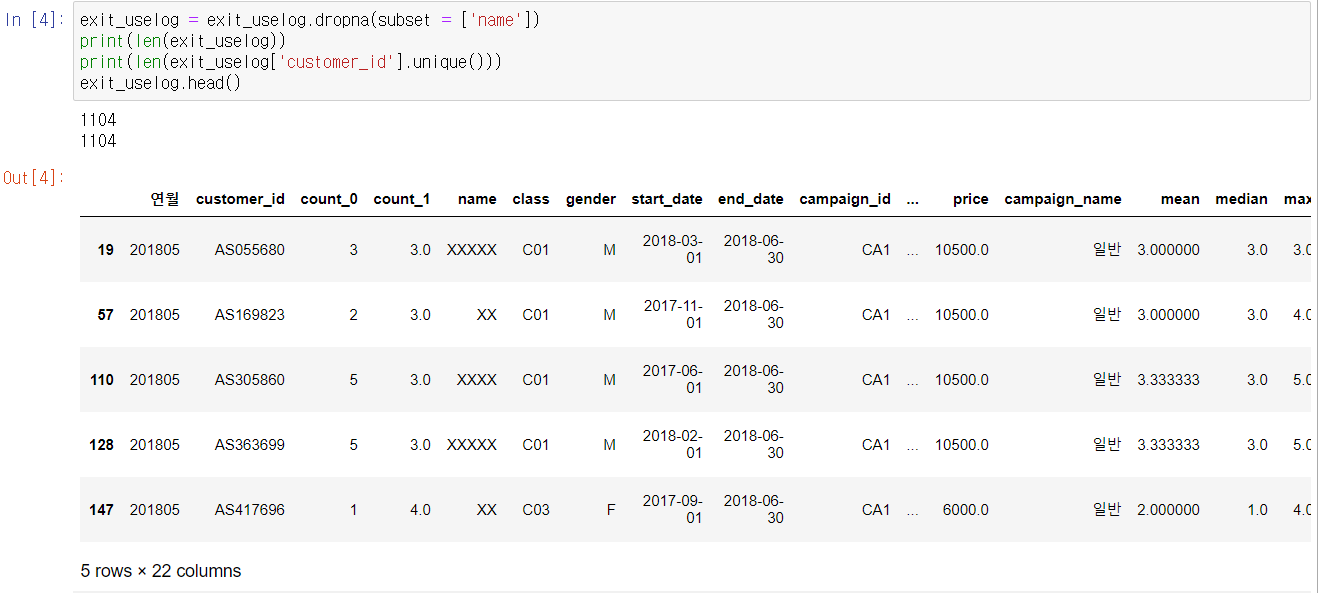
customer 데이터는 end_date 이외에 결측치가 존재하지 않는다. exit_uselog의 데이터 개수와 customer_id의 유니크한 개수를 세어보면 일치하는 것을 알 수 있다. 지금까지 작성한 데이터는 어떤 특정 회원이 그만두기 전월의 상태를 나타내는 데이터이다.
테크닉043 : 지속 회원의 데이터를 작성하자
지속 회원은 탈퇴 월이 없기 때문에 어떤 연월의 데이터를 작성해도 된다.
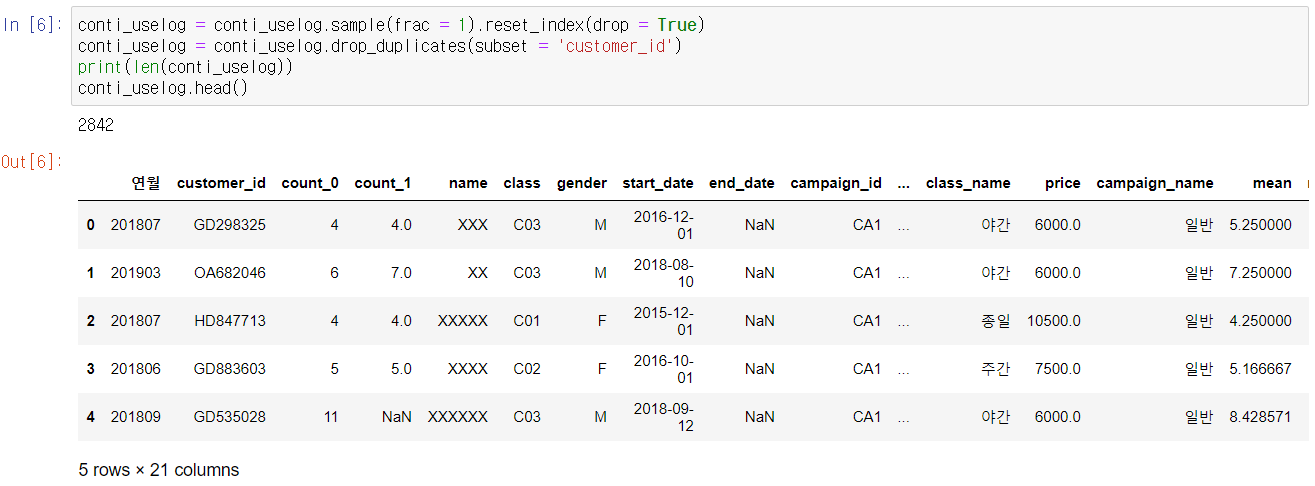
conti_customer = customer.loc[customer['is_deleted'] == 0]
conti_uselog = pd.merge(uselog, conti_customer, on = ['customer_id'], how = 'left')
print(len(conti_uselog))
conti_uselog = conti_uselog.dropna(subset = ['name'])
print(len(conti_uselog))
name 컬럼의 결손 데이터를 제거하고 탈퇴 회원을 제거한다. 이렇게 되면 데이터 개수는 33851개에서 27422개로 줄어든다. 탈퇴 데이터가 1104개밖에 없기 때문에 지속 회원 데이터 27422개를 전부 사용한다면 불균형한 데이터가 돼버린다. 간단히 지속 회원 데이터도 회원당 1개가 되게 언더 샘플링한다.
지속 회원 데이터도 작성했다. 이제 지속 회원 데이터와 탈퇴 회원 데이터를 세로로 결합해 보자.

코드를 실행하면 데이터의 개수와 처음 5개 데이터가 표시된다. 데이터 개수는 탈퇴 회원 1104개와 지속 고객 2842개가 결합되어 3946개가 된다.
테크닉044 : 예측할 달의 재적 기간을 작성하자
시간적 요소가 들어간 데이터이므로 재적 기간과 같은 데이터를 변수로 이용하는 것은 좋은 접근이다. 따라서 재적 기간 열을 추가한다.
predict_data['period'] = 0
predict_data['now_date'] = pd.to_datetime(predict_data['연월'], format = '%Y%m')
predict_data['start_date'] = pd.to_datetime(predict_data['start_date'])
for i in range(len(predict_data)):
delta = relativedelta(predict_data['now_date'][i], predict_data['start_date'][i])
predict_data['period'][i] = int(delta.years * 12 + delta.months)
predict_data.head()
재적 기간은 연월 컬럼과 start_date 컬럼의 차이로 구할 수 있다. 이렇게 해서 사용하고 싶은 설명 변수의 데이터 작성을 완료했다. 다음은 머신러닝을 위해 결측치 처리를 진행하자.
테크닉045 : 결측치를 제거하자
결측치가 존재하면 머신러닝을 할 수 없다. 결측치를 제거하기 위해 먼저 결측치의 수를 파악하자.
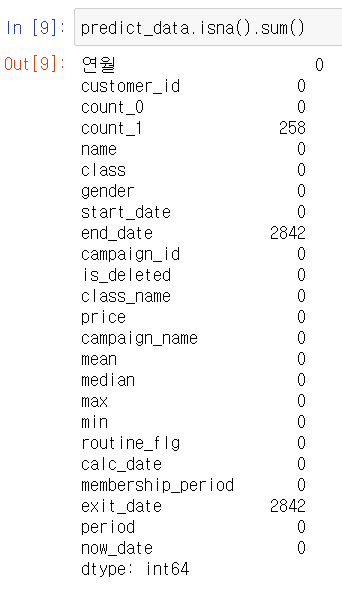
결과를 보면 end_date, exit_date, count_1에 결측치가 있는 것을 알 수 있다. end_date와 exit_date는 탈퇴 고객만 있으며 유지 회원은 결측치가 된다. 여기서는 count_1이 결손된 데이터만 제거한다.
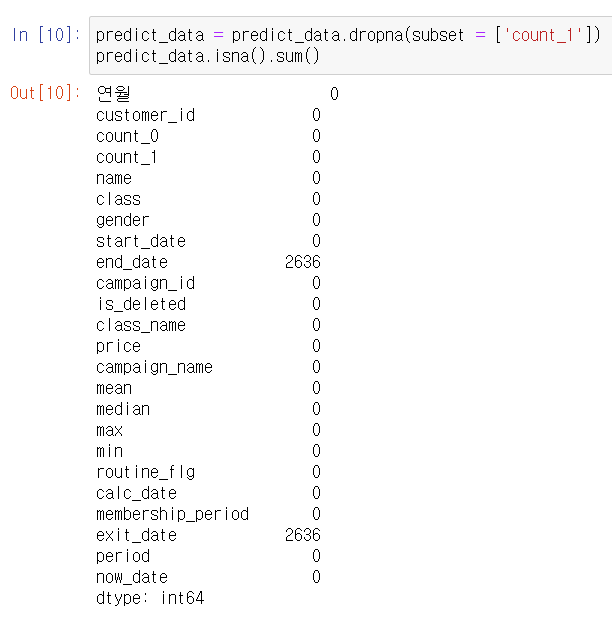
결측치를 확인해 보면 end_date와 exit_date에만 결측치가 있는 것을 확인할 수 있다. 이것으로 결측치 처리를 완료했다.
테크닉046 : 문자열 변수를 처리할 수 있게 가공하자
설명 변수로는 1개월 전의 이용 횟수 count_1, 카테고리 변수인 campaign_name, class_name, gender, routine_flg, period를 사용하고, 목적 변수로 탈퇴 플래그인 is_deleted를 사용한다.
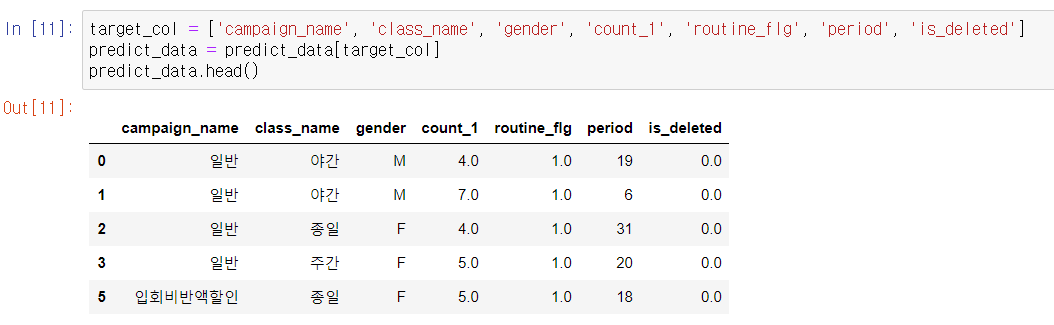
데이터가 추출된 것을 확인할 수 있다. 다음으로, 카테고리 변수를 이용해서 더미 변수를 만들어보자
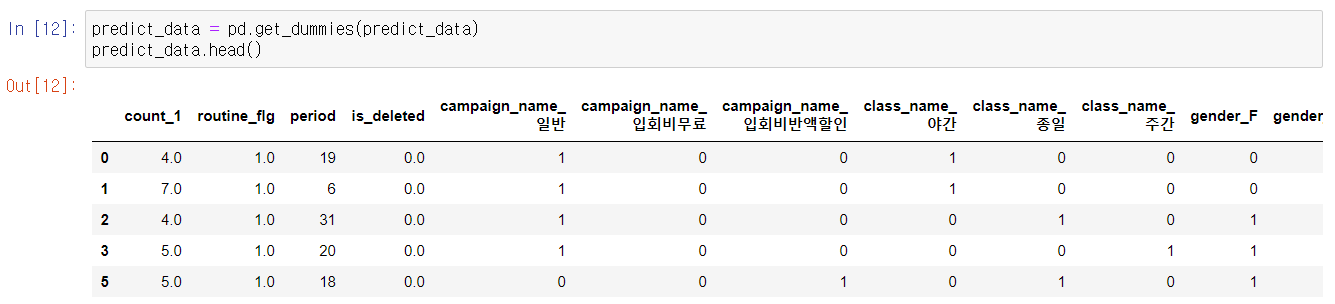
pandas에서 get_dummies를 이용하면 일괄적으로 더미 변수를 만들 수 있다. 문자열 데이터를 컬럼에 저장해 간단히 더미 변수로 만든다.
더미 변수에서는 한 가지 주의가 필요하다.
예를 들어 남성, 여성을 더미 변수로 만들 때 여성 컬럼이 1이면 여성을 의미하고 0이면 남성을 의미하기 때문에 일부러 남성 열을 만들 필요가 없다. 다른 변수도 마찬가지이다.
그렇기 때문에 각 더미 변수에서 하나씩 지워야 한다.
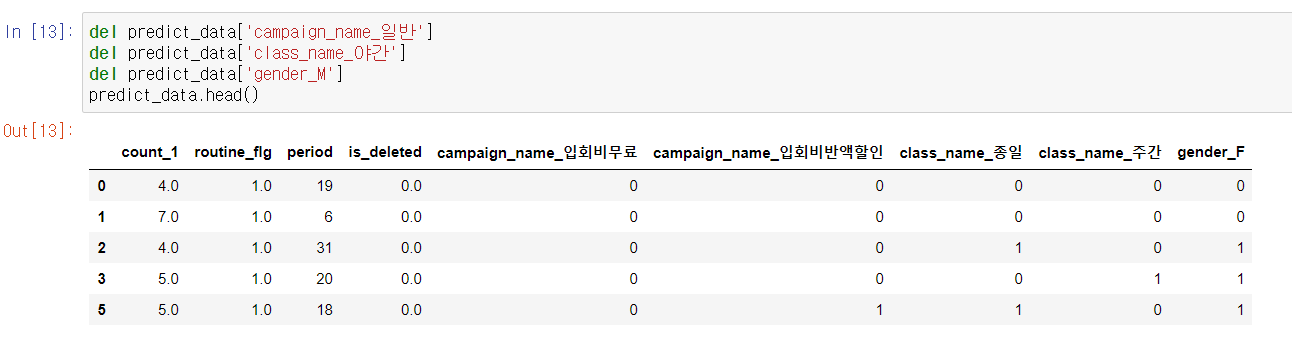
이제 머신러닝 모델을 구축할 준비가 됐다.
테크닉047 : 의사결정 트리를 사용해서 탈퇴 예측 모델을 구축하자
준비가 완료되었으니 의사결정 트리라는 알고리즘을 사용해서 모델을 구축한다.
from sklearn.tree import DecisionTreeClassifier
import sklearn.model_selection
exit = predict_data.loc[predict_data['is_deleted'] == 1]
conti = predict_data.loc[predict_data['is_deleted'] == 0].sample(len(exit))
X = pd.concat([exit, conti], ignore_index = True)
y = X['is_deleted']
del X['is_deleted']
X_train, X_test, y_train, y_test = sklearn.model_selection.train_test_split(X, y)
model = DecisionTreeClassifier(random_state = 0)
model.fit(X_train, y_train)
y_test_pred = model.predict(X_test)
print(y_test_pred)
1행과 2행은 필요한 라이브러리를 불러온다. 다음 블록에서는 탈퇴 데이터와 유지 데이터의 개수를 정리한다. 유지 데이터는 2842개, 탈퇴 데이터는 1104개였던 것을 유지 데이터에서 임의로 1104건을 추출해서 비율이 50대 50이 되게 한다. 그다음 블록에서는 앞에서 나눈 데이터를 결합해서 X에 저장하고 is_deleted 컬럼을 목적 변수 y에 저장한 뒤, X에서 is_deleted 열을 제거한다. 그리고 학습 데이터와 평가 데이터로 나눈다. 마지막 블록에서 모델을 생성하고 fit으로 학습용 데이터로 모델을 구축한다. 그다음, 구축한 모델을 이용해서 평가 데이터로 예측하고 결과를 출력한다. 출력 결과를 보면 0 또는 1이 표시되며, 1은 탈퇴, 0은 유지를 의미한다.
results_test = pd.DataFrame({'y_test' : y_test, 'y_pred' : y_test_pred})
results_test.head()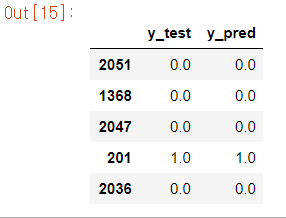
y_test와 예측 결과 y_test_pred를 results_test에 저장했다. 실행할 때마다 달라지므로 결과가 다를 수 있지만, 위에 결과를 보면 전부 다 정답으로 볼 수 있다.
다음으로, 이 모델을 평가해 보고 모델을 조금 튜닝해보자.
테크닉048 : 예측 모델을 평가하고 모델을 튜닝해 보자
우선 앞에서 작성한 results_test 데이터를 집계해서 정답률을 계산해 보자. 정답 수는 results_test 데이터의 y_test와 y_pred가 일치하는 개수이다. 이 개수를 전체 데이터 개수로 나누면 정답률이 계산된다.

출력 결과는 0.90 정도, 90% 정도의 정확도인 것을 알 수 있다.
평가용 데이터의 성능은 90.3%, 학습용 데이터의 성능은 97.5%이다. 학습용 데이터에 너무 맞춘 과적합 경향이 있다.
이런 경우 데이터 늘리기, 변수 재검토, 모델의 파라미터 변경과 같은 방법을 적용해 가면서 이상적인 모델로 만들어 간다. 여기서는 모델의 파라미터를 바꿔본다.
X = pd.concat([exit, conti], ignore_index = True)
y = X['is_deleted']
del X['is_deleted']
X_train, X_test, y_train, y_test = sklearn.model_selection.train_test_split(X, y)
model = DecisionTreeClassifier(random_state = 0, max_depth = 5)
model.fit(X_train, y_train)
print(model.score(X_test, y_test))
print(model.score(X_train, y_train))
스코어를 보면 전 결과보다 현재의 결과가 간격이 줄어들어 좀 더 좋은 모델이 만들어진다.
테크닉049 : 모델에 기여하는 변수를 확인하자.
변수의 기여율을 출력하자.
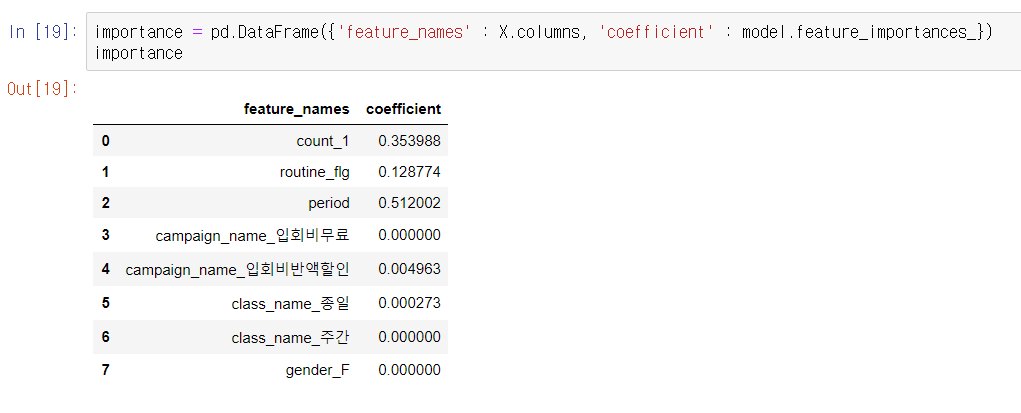
회귀와는 달리, model.feature_importances_로 변수 중요도를 얻을 수 있다. 실행 결과를 보면 1개월 전의 이용 횟수, 정기 이용 여부, 재적 기간이 기여하고 있다.
이제 마지막으로 변수를 작성해서 예측해보자.
테크닉050 : 회원 탈퇴를 예측하자
설명 변수를 참고로 예측을 위한 데이터를 작성하자.
count_1 = 4
routing_flg = 1
period = 10
campaign_name = '입회비무료'
class_name = '종일'
gender = 'M'변수가 정의되면 데이터를 가공한다.
if campaign_name == '입회비반값할인':
campaign_name_list = [1, 0]
elif campaign_name == '입회비무료':
campaign_name_list = [0, 1]
elif campaign_name == '일반':
campaign_name_list = [0, 0]
if class_name == '종일':
class_name_list = [1, 0]
elif class_name == '주간':
class_name_list = [0, 1]
elif class_name == '야간':
class_name_list = [0, 0]
if gender == 'M':
gender_list = [0]
elif gender == 'F':
gender_list = [1]
input_data = [count_1, routing_flg, period]
input_data.extend(campaign_name_list)
input_data.extend(class_name_list)
input_data.extend(gender_list)카테고리 변수를 if 문으로 분기하면서 더미 변수로 작성한다.

예측한 분류 결과를 보면, 이번의 경우 1, 즉 탈퇴가 예상된다. 2행에서 출력한 것이 각각 0과 1의 예측 확률이다. 이번 경우에는 98%의 확률로 탈퇴라고 예측했다.
변수를 바꿔가면서 예측을 할 수 있다. 실제로는 구축한 모델을 시스템화해 이용하는 경우가 많다. 예측 모델을 구축하는 것은 신속하게 자동으로 탈퇴 회원을 찾을 수 있어 인간의 감각뿐만 아니라 데이터를 기반으로 판단할 수 있게 해 준다.
이것으로 2부의 머신러닝 구축까지 일련의 흐름을 알아봤다.
'파이썬' 카테고리의 다른 글
| [파이썬 실습] 정규화 모델 실습(1) (0) | 2021.06.05 |
|---|---|
| [빅데이터분석기사 실기] - 작업형 1유형 (0) | 2021.06.04 |
| 파이썬 데이터 분석 실무 테크닉 100 -머신러닝(2) (0) | 2021.06.01 |
| [파이썬 실습] Logistic Regression 실습 (0) | 2021.05.31 |
| [파이썬 실습] Linear Regression 실습 (0) | 2021.05.28 |